Text-To-Speech And Back Again With AWS (Part 2)
Text-To-Speech And Back Again With AWS (Part 2)
Philip Kiely2019-10-02T12:30:59+02:002019-10-02T20:35:54+00:00
This is the second half of a series on transforming content between text and speech on AWS. In part one, we used Amazon Polly to narrate blog posts and embedded the content in a website using an audio tag. In this article, we will use speech-to-text to draft transcripts of podcasts and interviews for publication. Finally, we will evaluate the overall accuracy of these format-transformation technologies by running a few samples through round-trip transcriptions.
Speech-To-Text Project
In 2012, Patrick McKenzie (a.k.a. patio11, of Kalzumeus and Stripe) and Ramit Sethi (of I Will Teach You To Be Rich) sat down and recorded two hour-long podcasts. As I am a fan of both of their work, I probably would have listened to the podcasts, but I definitely wouldn’t have listened to them several times each. The transcripts, on the other hand, I can reread and reference at my leisure. I also freely recommend the series when talking to people about freelancing, knowing that I am giving them a resource that takes a quarter the time to read that it takes to listen to. Even though the content of the podcasts and transcripts are exactly the same, the combination is 10× as useful as the podcast alone.
In the first transcript, McKenzie says that he paid 75 dollars and waited a couple of days to have the podcast transcribed by a professional service. His other option was to transcribe it himself. When I worked for my college’s newspaper, I frequently transcribed interviews. Over time, I got more practiced at the skill and improved from taking four minutes of transcribing per minute of audio to three minutes per minute. While I imagine that a professional with specialized equipment and a faster typing speed could drop below two minutes per minute, as an amateur transcriber McKenzie likely saved himself five or six hours of work by paying for the service.
Seven years later, it seems like he should have another option: an automated transcription with Amazon Web Services. As we’ll see, the transcription would require significantly more editing before it would be publication-ready, but automated transcription has two killer features compared to hiring a professional: he would have gotten the transcription back in real time for about a dollar. In this article, I’ll explain how you can use Speech-to-Text on AWS to easily make your content multi-format and ideas for using Amazon Transcribe in more complex applications.
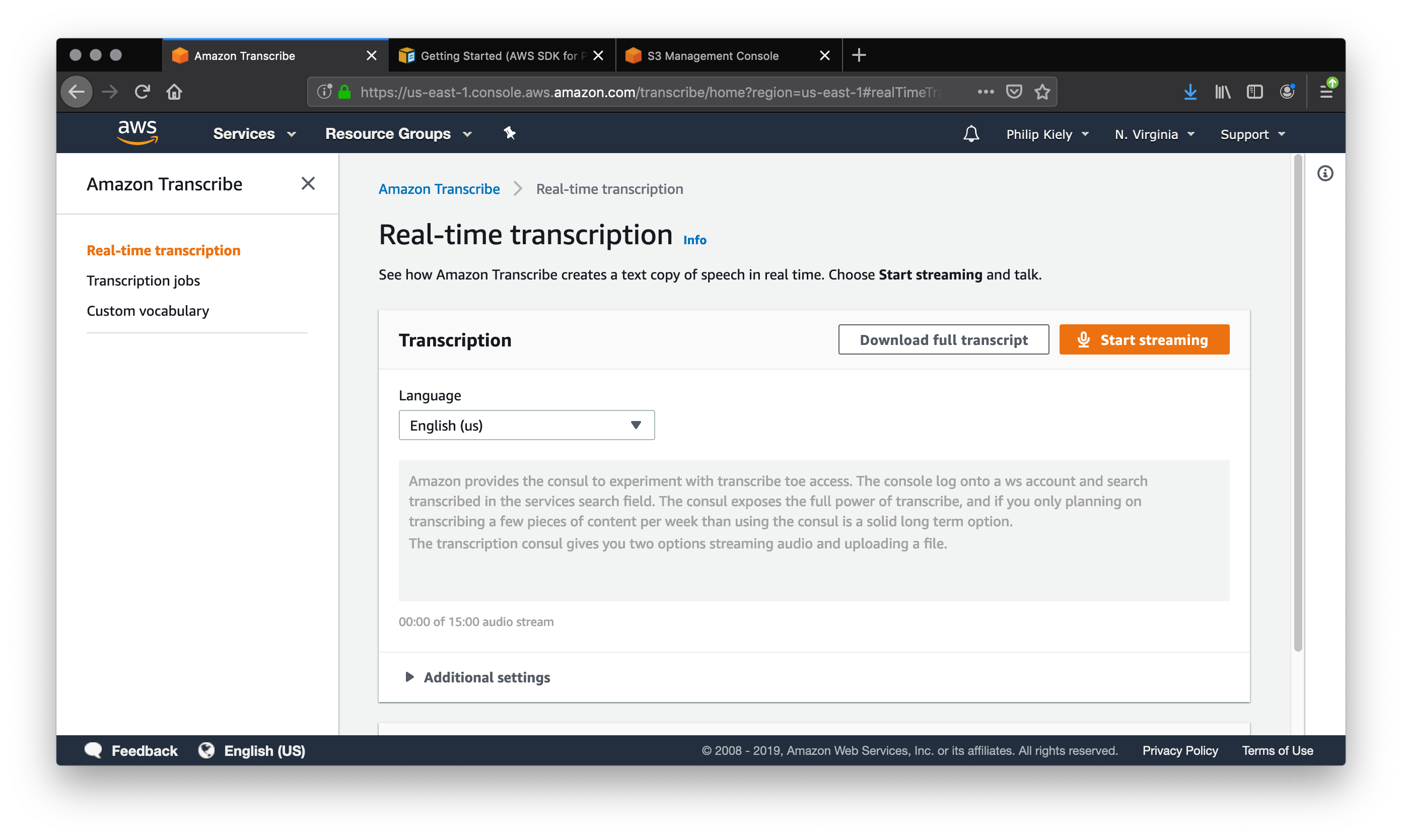
Amazon provides a console to experiment with Transcribe. To access the console, log on to your AWS account and search “Transcribe” in the services search field. The console exposes the full power of Transcribe, and if you’re only planning on transcribing a few pieces of content per week then using the console is a solid long-term option. The transcription console gives you two options: streaming audio and uploading a file.
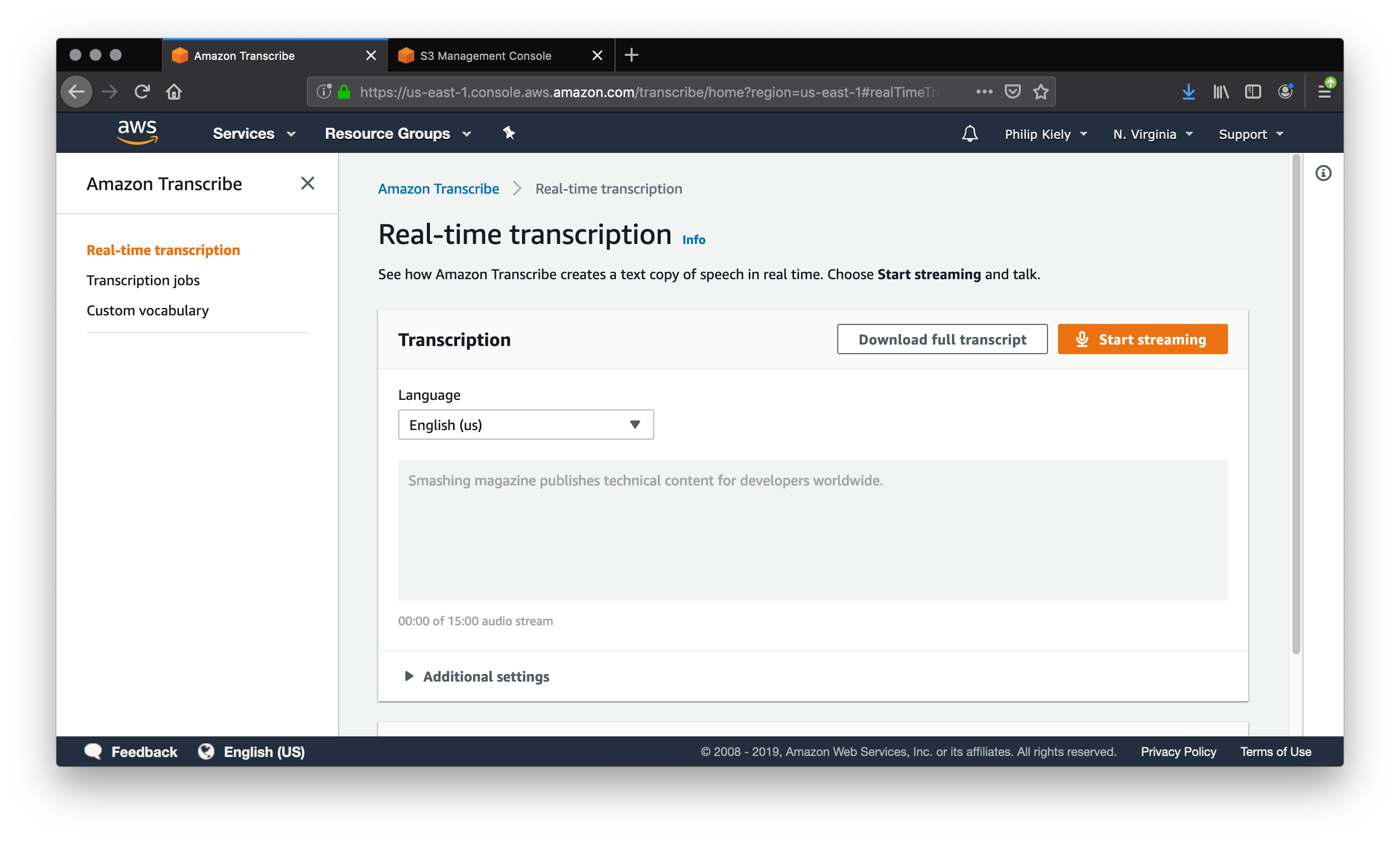
The “real-time transcription” tab offers the ability to speak into the microphone and have a transcription generated in real time. Speaking deliberately, and with my computer’s onboard microphone, I was able to transcribe the sentence “Smashing Magazine publishes technical content for developers worldwide” on the first try. However, when I tried to transcribe the previous paragraph at a more conversational speed and articulation, there were numerous errors.
“Amazon provides a consul to experiment with transcribe access. The console log onto a ws account and search transcribed in the services search field, The consul exposes the full power of transcribed. And if you only planning on transcribing a few pieces of content a week than using the consul is a solid long term option. The transcription Council gives you two options streaming audio and uploaded a file.”
In addition to simply missing some words, Transcribe has issues with homophones and punctuation. In the first sentence, it transcribed “console” as “consul.” This homophone error can only be corrected by evaluating each transcribed word in the context of the sentence and adjusting according to the algorithm’s best guess. The first sentence also runs into the second, which throws off the grammatical structure and meaning of the entire rest of the paragraph. Beyond contextual clues, Amazon Transcribe seems to use pauses to determine punctuation. That said, I am using a built-in microphone, transcribing in real time, and to be honest I don’t have the clearest speaking voice. Let’s see if we can find improvements by mitigating each of these factors.
I used a Blue Yeti, a midrange all-purpose recording microphone, to stream audio into the console. As you can see in the image below, improved audio quality did not significantly improve transcription quality. I hypothesize that while a poor quality audio input would further degrade the text’s accuracy, improvement past the threshold of a built-in microphone or cheap webcam does not provide the quality transcription that we are looking for.
Using the same microphone, I recorded the same paragraph as an .mp3 file and uploaded it for transcription. To do the same, navigate to the “Transcription Jobs” panel and click the orange button with the text “Create Job.” This will bring you to a form where you can configure the transcription job.
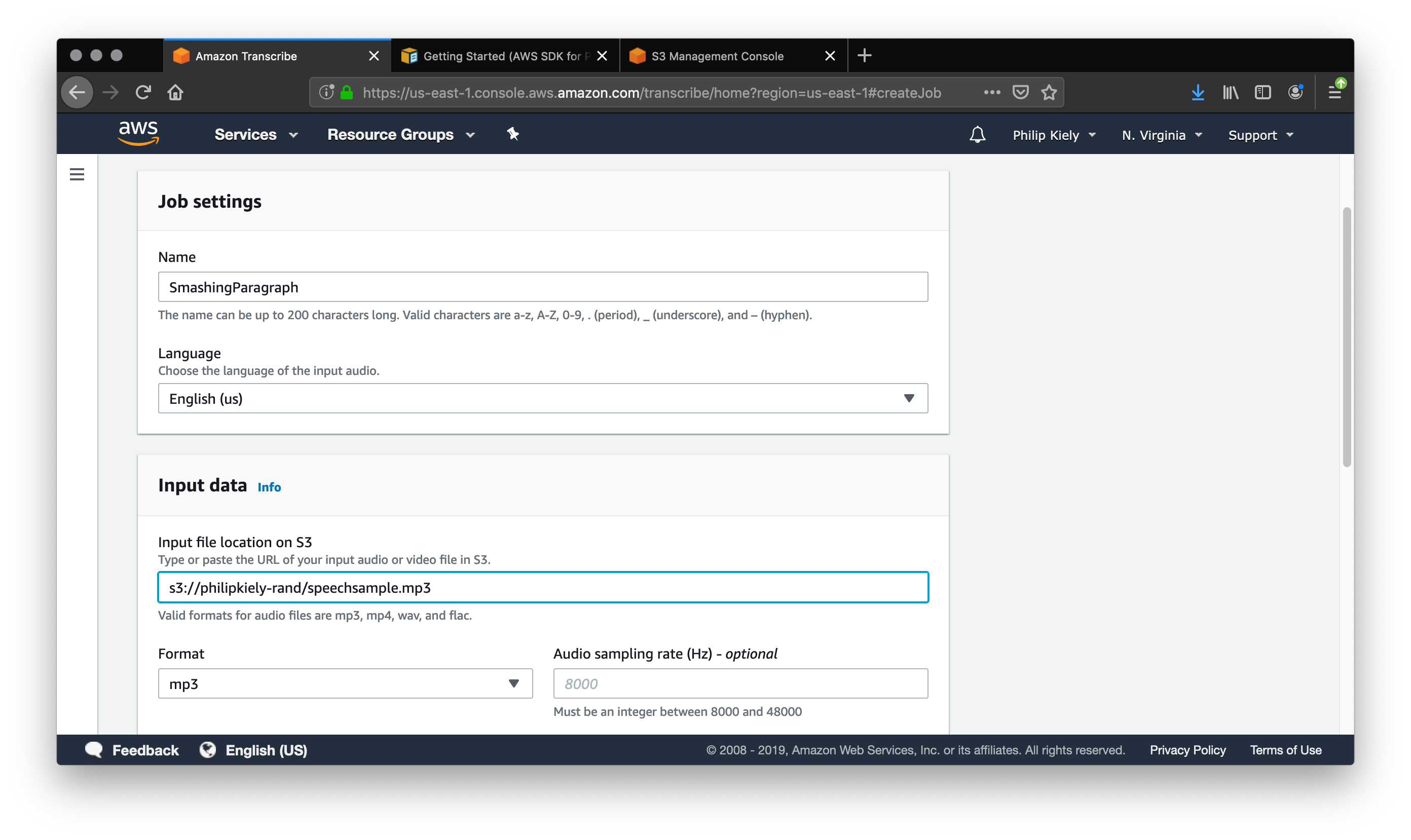
The job name is arbitrary, just choose something that will be meaningful to you when you review the completed jobs. You can select from about a dozen languages, with English and Spanish available in regional variants. The transcription service draws its input from S3, so you’ll need to upload your audio file to the storage service before you can run the job. You can upload the file in one of four supported formats: .mp3, .mp4, .wav, and .flac.

If you want to keep the output data in a permanent location, change “Data location” to “Customer specified” and enter the name of an S3 bucket that you can write to. Finally, you can choose between two identification options. Channel identification tags input with the channel that it came from in the audio file, while “Speaker identification” attempts to recognize distinct voices in the audio. If you are transcribing a multi-person podcast or interview, Speaker identification is a useful feature, but it is not applicable to this simple test.
Inspecting the output, unfortunately, reveals that the transcription is no more accurate than the real-time console transcription. However, running a transcription job does provide more data. In addition to the transcription text, the job outputs JSON with each word, its confidence score, and alternate words considered, if any. If you want to write your own natural language processing code to try to improve the readability of the output, this data will give you what you need to get started.
Finally, I had a friend who hosts a local radio show narrate the same paragraph for live transcription. Despite his steady pace and clear enunciation, the resulting text was no more accurate than any of my live transcription attempts. While a professional narrator may be able to achieve even more specific pronunciation, the technology is really only useful if it is widely usable.
Unfortunately, it seems that the transcription quality is too low to fully automate our proposed use case. Depending on your typing speed, running audio through Amazon Transcribe and then editing by hand may be faster than simple manual transcription, but it is not a turnkey solution for speech-to-text that compares to what exists for text-to-speech. For specific domains, you can define Custom Vocabularies to improve transcription accuracy, but out of the box, the service is insufficiently advanced.
As with most of its services, AWS offers an API for using Transcribe. Unless you have a large number of files to transcribe or you need to transcribe audio in response to events, I would recommend using the console and save yourself the time of setting up programmatic access.
To use Transcribe from the AWS CLI, you’ll need a JSON file and a terminal command.
aws transcribe start-transcription-job
--region YOUR_REGION_HERE
--cli-input-json YOUR_FILE_PATH.jsonAt YOUR_FILE_PATH.json, you’ll need a .json file with four pieces of information. As above, you can set any meaningful string as the TranscriptionJobName and any supported language as the LanguageCode. The CLI supports the same four media file formats and still reads the media file from S3.
{
"TranscriptionJobName": "request ID",
"LanguageCode": "en-US",
"MediaFormat": "mp3",
"Media": {
"MediaFileUri": "https://YOUR_S3_BUCKET/YOUR_MEDIA_FILE.mp3"
}
}This kind of access is also available through a Python SDK. Amazon recommends Transcribe for voice analytics, search and compliance, advertising, and closed-captioning media. In each of these cases, the transcribed text is an input to another system like Amazon Comprehend rather than the final output. Thus, as a developer, it is important to design your system and limit its use cases to tolerate the range of errors that Transcribe will feed into your application.
Note: For more on using Amazon Transcribe and other services programmatically, check out Amazon’s getting started guide.
Round Trip Accuracy
While the live performance of Amazon Transcribe was somewhat disappointing, we can investigate the theoretical maximum accuracy of the system by transcribing something that was read by Amazon Polly. The two services should be using compatible pronunciation libraries and speech cadences, so text input into Amazon Polly should survive the round trip more or less intact. Of course, we will stick with the same test paragraph.
Lo and behold, this is the only strategy that has made the transcription noticeably better:
“Amazon provides a console to experiment with transcribe. To access the console, log onto your AWS account and search transcribing the service’s search field. The console exposes the full power of transcribe, and if you’re only planning on transcribing a few pieces of content per week than using the console is a solid long term option. The Transcription council gives you two options. Streaming audio and uploading a file.”
Stubborn errors persist (“council” versus “console” comes in at 70% confidence) but overall the text is a few edits away from useable. However, most of us don’t speak like synthesized robots, so this quality is unavailable to us at the time of writing.
Conclusion
While the quality of output speech and text are noticeably lesser than that of a person, these services cost so little that they are a strong alternative for many applications. Text-to-speech, at 4 dollars per million characters (16 dollars per million for the superior neural voices), can narrate articles in seconds for pennies. Speech-to-text, at .04 cents per second, can transcribe podcasts in minutes for about a dollar. Of course, prices may change over time, but historically as technologies like these improve, they tend to become less expensive and more effective.
Because of the low cost, you can experiment with these technologies for things like improving your personal productivity. When biking or driving to work, it is impossible to type notes or an outline a project, however, speaking and automatically transcribing a stream-of-consciousness narration would get a lot of planning done. Journalists frequently transcribe long interviews, a process which AWS can automate by tagging the voices of people speaking in a recording. On the other side of the writing process, having a steady, robotic voice read your work back to you can help you identify errors and awkward phrasing.
These technologies already have a number of use cases, but that will only expand over time as the technologies improve. While text-to-speech is reaching near-perfect accuracy in pronunciation, especially when assisted by pronunciation alphabets and tags, the synthesized voice still doesn’t sound fully natural. Speech-to-text systems are pretty good at transcribing clear speech but still struggle with punctuation, homophones, and even moderately quick speech. Once the technologies overcome these challenges, I anticipate that most applications will have a use for at least one of them.
