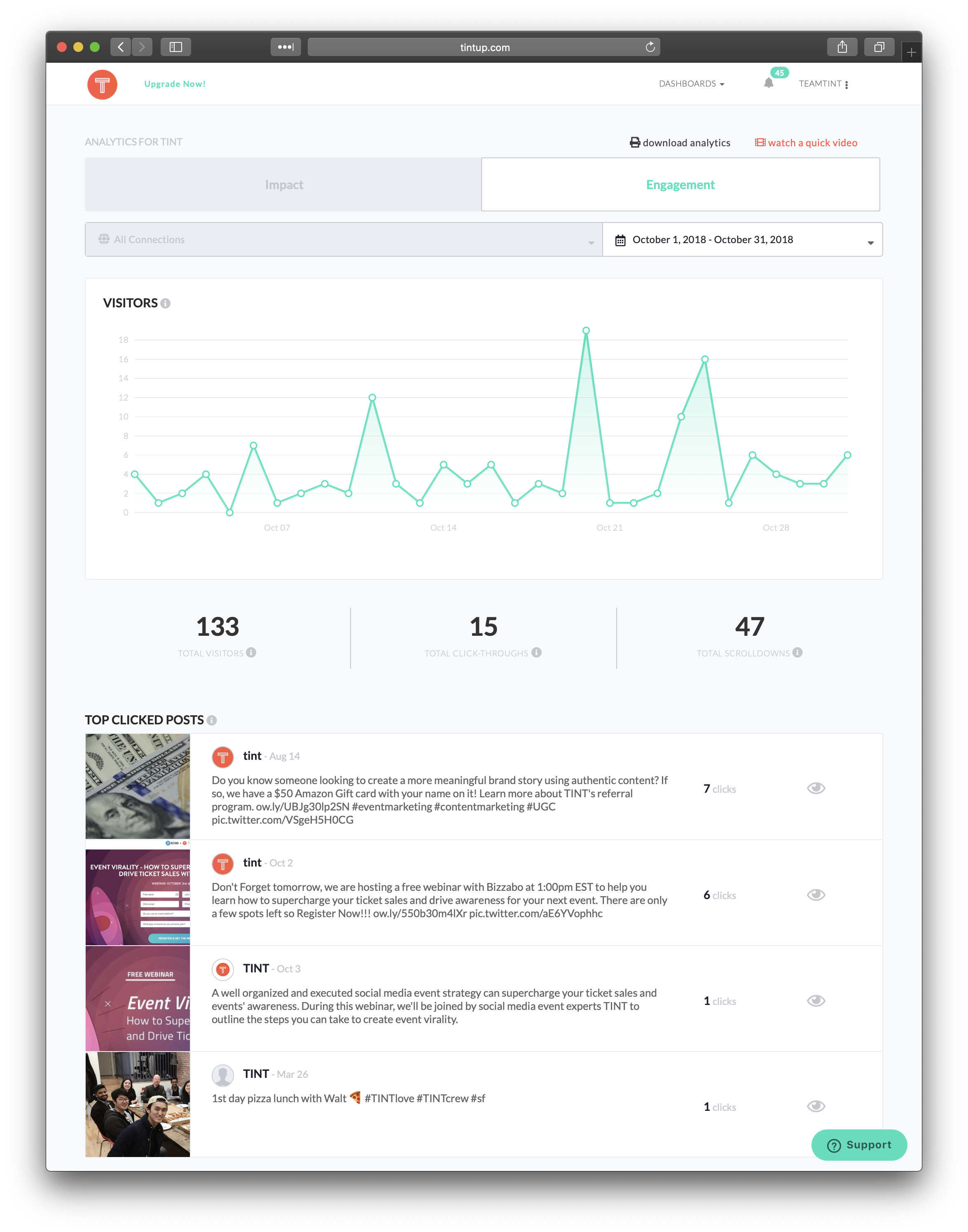
I Spun up a Scalable WordPress Server Environment with Trellis, and You Can, Too

A few years back, my fledgling website design agency was starting to take shape; however, we had one problem: managing clients’ web servers and code deployments. We were unable to build a streamlined process of provisioning servers and maintaining operating system security patches. We had the development cycle down pat, but server management became the bane of our work. We also needed tight control over each server depending on a site’s specific needs. Also, no, shared hosting was not the long term solution.
I began looking for a prebuilt solution that could solve this problem but came up with no particular success. At first, I manually provisioned servers. This process quickly proved to be both monotonous and prone to errors. I eventually learned Ansible and created a homegrown conglomeration of custom Ansible roles, bash scripts and Ansible Galaxy roles that further simplified the process — but, again, there were still many manual steps needed to take before the server was 100%.
I’m not a server guy (nor do I pretend to be one), and at this point, it became apparent that going down this path was not going to end well in the long run. I was taking on new clients and needed a solution, or else I would risk our ability to be sustainable, let alone grow. I was spending gobs of time typing arbitrary sudo apt-get update commands into a shell when I should have been managing clients or writing code. That’s not to mention I was also handling ongoing security updates for the underlying operating system and its applications.
Tell me if any of this sounds familiar.
Serendipitously, at this time, the team at Roots had released Trellis for server provisioning; after testing it out, things seemed to fall into place. A bonus is that Trellis also handles complex code deployments, which turned out to be something else I needed as most of the client sites and web applications that we built have a relatively sophisticated build process for WordPress using Composer, npm, webpack, and more. Better yet, it takes just minutes to jumpstart a new project. After spending hundreds of hours perfecting my provisioning process with Trellis, I hope to pass what I’ve learned onto you and save you all the hours of research, trials, and manual work that I wound up spending.
A note about Bedrock
We’re going to assume that your WordPress project is using Bedrock as its foundation. Bedrock is maintained by the same folks who maintain Trellis and is a “WordPress boilerplate with modern development tools, easier configuration, and an improved folder structure.” This post does not explicitly explain how to manage Bedrock, but it is pretty simple to set up, which you can read about in its documentation. Trellis is natively designed to deploy Bedrock projects.
A note about what should go into the repo of a WordPress site
One thing that this entire project has taught me is that WordPress applications are typically just the theme (or the child theme in the parent/child theme relationship). Everything else, including plugins, libraries, parent themes and even WordPress itself are just dependencies. That means that our version control systems should typically include the theme alone and that we can use Composer to manage all of the dependencies. In short, any code that is managed elsewhere should never be versioned. We should have a way for Composer to pull it in during the deployment process. Trellis gives us a simple and straightforward way to accomplish this.
Getting started
Here are some things I’m assuming going forward:
- The code for the new site in the directory
~/Sites/newsite - The staging URL is going to be
https://newsite.statenweb.com - The production URL is going to be
https://newsite.com - Bedrock serves as the foundation for your WordPress application
- Git is used for version control and GitHub is used for storing code. The repository for the site is:
git@github.com:statenweb/newsite.git
I am a little old school in my local development environment, so I’m foregoing Vagrant for local development in favor of MAMP. We won’t go over setting up the local environment in this article.
I set up a quick start bash script for MacOS to automate this even further.
The two main projects we are going to need are Trellis and Bedrock. If you haven’t done so already, create a directory for the site (mkdir ~/Sites/newsite) and clone both projects from there. I clone Trellis into a /trellis directory and Bedrock into the /site directory:
cd ~/Sites/newsite
git clone git@github.com:roots/trellis.git
git clone git@github.com:roots/bedrock.git site
cd trellis
rm -rf .git
cd ../site
rm -rf .gitThe last four lines enable us to version everything correctly. When you version your project, the repo should contain everything in ~/Sites/newsite.
Now, go into trellis and make the following changes:
First, open ~/Sites/newsite/trellis/ansible.cfg and add these lines to the bottom of the [defaults] key:
vault_password_file = .vault_pass
host_key_checking = FalseThe first line allows us to use a .vault_pass file to encrypt all of our vault.yml files which are going to store our passwords, sensitive data, and salts.
The second host_key_checking = False can be omitted for security as it could be considered somewhat dangerous. That said, it’s still helpful in that we do not have to manage host key checking (i.e., typing yes when prompted).
Ansible vault password
Next, let’s create the file ~/Sites/newsite/trellis/.vault_pass and enter a random hash of 64 characters in it. We can use a hash generator to create that (see here for example). This file is explicitly ignored in the default .gitignore, so it will (or should!) not make it up to the source control. I save this password somewhere extremely secure. Be sure to run chmod 600 .vault_pass to restrict access to this file.
The reason we do this is so we can store encrypted passwords in the version control system and not have to worry about exposing any of the server’s secrets. The main thing to call out is that the .vault_pass file is (and should not be) not committed to the repo and that the vault.yml file is properly encrypted; more on this in the “Encrypting the Secret Variables” section below.
Setting up target hosts

Next, we need to set up our target hosts. The target host is the web address where Trellis will deploy our code. For this tutorial, we are going to be configuring newsite.com as our production target host and newsite.statenweb.com as our staging target host. To do this, let’s first update the production servers address in the production host file, stored in ~/Sites/newsite/trellis/hosts/production to:
[production]
newsite.com
[web]
newsite.comNext, we can update the staging server address in the staging host file, which is stored in ~/Sites/newsite/trellis/hosts/staging to:
[staging]
newsite.statenweb.com
[web]
newsite.statenweb.comSetting up GitHub SSH Keys
For deployments to be successful, SSH keys need to be working. Trellis takes advantage of how GitHub’ exposes all public (SSH) keys so that you do not need to add keys manually. To set this up go into the group_vars/all/users.yml and update both the web_user and the admin_user object’s keys value to include your GitHub username. For example:
users:
- name: '{{ web_user }}'
groups:
- '{{ web_group }}'
keys:
- https://github.com/matgargano.keys
- name: '{{ admin_user }}'
groups:
- sudo
keys:
- https://github.com/matgargano.keysOf course, all of this assumes that you have a GitHub account with all of your necessary public keys associated with it.
Site Meta
We store essential site information in:
~/Sites/newsite/trellis/group_vars/production/wordpress_sites.ymlfor production~/Sites/newsite/trellis/group_vars/staging/wordpress_sites.ymlfor staging.
Let’s update the following information for our staging wordpress_sites.yml:
wordpress_sites:
newsite.statenweb.com:
site_hosts:
- canonical: newsite.statenweb.com
local_path: ../site
repo: git@github.com:statenweb/newsite.git
repo_subtree_path: site
branch: staging
multisite:
enabled: false
ssl:
enabled: true
provider: letsencrypt
cache:
enabled: falseThis file is saying that we:
- removed the site hosts redirects as they are not needed for staging
- set the canonical site URL (
newsite.statenweb.com) for the site key (newsite.statenweb.com) - defined the URL for the repository
- the git repo branch that gets deployed to this target is
staging, i.e., we are using a separate branch namedstagingfor our staging site - enabled SSL (set to true), which will also install an SSL certificate when the box provisions
Let’s update the following information for our production wordpress_sites.yml:
wordpress_sites:
newsite.com:
site_hosts:
- canonical: newsite.com
redirects:
- www.newsite.com
local_path: ../site # path targeting local Bedrock site directory (relative to Ansible root)
repo: git@github.com:statenweb/newsite.git
repo_subtree_path: site
branch: master
multisite:
enabled: false
ssl:
enabled: true
provider: letsencrypt
cache:
enabled: falseAgain, what this translates to is that we:
- set the canonical site URL (
newsite.com) for the site key (newsite.com) - set a redirect for
www.newsite.com - defined the URL for the repository
- the git repo branch that gets deployed to this target is
master, i.e., we are using a separate branch namedmasterfor our production site - enabled SSL (set to true), which will install an SSL certificate when you provision the box
In the wordpress_sites.yml you can further configure your server with caching, which is beyond the scope of this guide. See Trellis’ documentation on FastCGI Caching for more information.
Secret Variables

There are going to be several secret pieces of information for both our staging and production site including the root user password, MySQL root password, site salts, and more. As referenced previously, Ansible Vault and using .vault_pass file makes this a breeze.
We store this secret site information in:
~/Sites/newsite/trellis/group_vars/production/vault.ymlfor production~/Sites/newsite/trellis/group_vars/staging/vault.ymlfor staging
Let’s update the following information for our staging vault.yml:
vault_mysql_root_password: pK3ygadfPHcLCAVHWMX
vault_users:
- name: "{{ admin_user }}"
password: QvtZ7tdasdfzUmJxWr8DCs
salt: "heFijJasdfQbN8bA3A"
vault_wordpress_sites:
newsite.statenweb.com:
env:
auth_key: "Ab$YTlX%:Qt8ij/99LUadfl1:U]m0ds@N<3@x0LHawBsO$(gdrJQm]@alkr@/sUo.O"
secure_auth_key: "+>Pbsd:|aiadf50;1Gz;.Z{nt%Qvx.5m0]4n:L:h9AaexLR{1B6.HeMH[w4$>H_"
logged_in_key: "c3]7HixBkSC%}-fadsfK0yq{HF)D#1S@Rsa`i5aW^jW+W`8`e=&PABU(s&JH5oPE"
nonce_key: "5$vig.yGqWl3G-.^yXD5.ddf/BsHx|i]>h=mSy;99ex*Saj<@lh;3)85D;#|RC="
auth_salt: "Wv)[t.xcPsA}&/]rhxldafM;h(FSmvR]+D9gN9c6{*hFiZ{]{,#b%4Um.QzAW+aLz"
secure_auth_salt: "e4dz}_x)DDg(si/8Ye&U.p@pB}NzHdfQccJSAh;?W)>JZ=8:,i?;j$bwSG)L!JIG"
logged_in_salt: "DET>c?m1uMAt%hj3`8%_emsz}EDM7R@44c0HpAK(pSnRuzJ*WTQzWnCFTcp;,:44"
nonce_salt: "oHB]MD%RBla*#x>[UhoE{hm{7j#0MaRA#fdQcdfKe]Y#M0kQ0F/0xe{cb|g,h.-m"Now, let’s update the following information for our production vault.yml:
vault_mysql_root_password: nzUMN4zBoMZXJDJis3WC
vault_users:
- name: "{{ admin_user }}"
password: tFxea6ULFM8CBejagwiU
salt: "9LgzE8phVmNdrdtMDdvR"
vault_wordpress_sites:
newsite.com:
env:
db_password: eFKYefM4hafxCFy3cash
# Generate your keys here: https://roots.io/salts.html
auth_key: "|4xA-:Pa=-rT]&!-(%*uKAcd</+m>ix_Uv,`/(7dk1+;b|ql]42gh&HPFdDZ@&of"
secure_auth_key: "171KFFX1ztl+1I/P$bJrxi*s;}.>S:{^-=@*2LN9UfalAFX2Nx1/Q&i&LIrI(BQ["
logged_in_key: "5)F+gFFe}}0;2G:k/S>CI2M*rjCD-mFX?Pw!1o.@>;?85JGu}#(0#)^l}&/W;K&D"
nonce_key: "5/[Zf[yXFFgsc#`4r[kGgduxVfbn::<+F<$jw!WX,lAi41#D-Dsaho@PVUe=8@iH"
auth_salt: "388p$c=GFFq&hw6zj+T(rJro|V@S2To&dD|Q9J`wqdWM&j8.KN]y?WZZj$T-PTBa"
secure_auth_salt: "%Rp09[iM0.n[ozB(t;0vk55QDFuMp1-=+F=f%/Xv&7`_oPur1ma%TytFFy[RTI,j"
logged_in_salt: "dOcGR-m:%4NpEeSj>?A8%x50(d0=[cvV!2x`.vB|^#G!_D-4Q>.+1K!6FFw8Da7G"
nonce_salt: "rRIHVyNKD{LQb$uOhZLhz5QX}P)QUUo!Yw]+@!u7WB:INFFYI|Ta5@G,j(-]F.@4"The essential lines for both are that:
- The site key must match the key in
wordpress_sites.ymlwe are usingnewsite.statenweb.com:for staging andnewsite.com:for production - I randomly generated
vault_mysql_root_password,password,salt,db_password, anddb_password. I used Roots’ helper to generate the salts.
I typically use Gmail’s SMTP servers using the Post SMTP plugin, so there’s no need for me to edit the ~/Sites/newsite/group_vars/all/vault.yml.
Encrypting the Secret Variables

As previously mentioned we use Ansible Vault to encrypt our vault.yml files. Here’s how to encrypt the files and make them ready to be stored in our version control system:
cd ~/Sites/newsite/trellis
ansible-vault encrypt group_vars/staging/vault.yml group_vars/production/vault.ymlNow, if we open either ~/Sites/newsite/trellis/group_vars/staging/vault.yml or ~/Sites/newsite/trellis/group_vars/production/vault.yml, all we’ll get is garbled text. This is safe to be stored in a repository as the only way to decrypt it is to use the .vault_pass. It goes without saying to make extra sure that the .vault_pass itself does not get committed to the repository.
A note about compiling, transpiling, etc.
Another thing that’s out of scope is setting up Trellis deployments to handle a build process using build tools such as npm and webpack. This is example code to handle a custom build that could be included in ~/Sites/newsite/trellis/deploy-hooks/build-before.yml:
---
-
args:
chdir: "{{ project.local_path }}/web/app/themes/newsite"
command: "npm install"
connection: local
name: "Run npm install"
-
args:
chdir: "{{ project.local_path }}/web/app/themes/newsite"
command: "npm run build"
connection: local
name: "Compile assets for production"
-
name: "Copy Assets"
synchronize:
dest: "{{ deploy_helper.new_release_path }}/web/app/themes/newsite/dist/"
group: no
owner: no
rsync_opts: "--chmod=Du=rwx,--chmod=Dg=rx,--chmod=Do=rx,--chmod=Fu=rw,--chmod=Fg=r,--chmod=Fo=r"
src: "{{ project.local_path }}/web/app/themes/newsite/dist/"These are instructions that build assets and moves them into a directory that I explicitly decided not to version. I hope to write a follow-up guide that dives specifically into that.
Provision

I am not going to go in great detail about setting up the servers themselves, but I typically would go into DigitalOcean and spin up a new droplet. As of this writing, Trellis is written on Ubuntu 18.04 LTS (Bionic Beaver) which acts as the production server. In that droplet, I would add a public key that is also included in my GitHub account. For simplicity, I can use the same server as my staging server. This scenario is likely not what you would be using; maybe you use a single server for all of your staging sites. If that is the case, then you may want to pay attention to the passwords configured in ~/Sites/newsite/trellis/group_vars/staging/vault.yml.
At the DNS level, I would map the naked A record for newsite.com to the IP address of the newly created droplet. Then I’d map the CNAME www to @. Additionally, the A record for newsite.statenweb.com would be mapped to the IP address of the droplet (or, alternately, a CNAME record could be created for newsite.statenweb.com to newsite.com since they are both on the same box in this example).
After the DNS propagates, which can take some time, the staging box can be provisioned by running the following commands.
First off, it;’s possible you may need to run this before anything else:
ansible-galaxy install -r requirements.ymlThen, install the required Ansible Galaxy roles before proceeding:
cd ~/Sites/newsite/trellis
ansible-playbook server.yml -e env=stagingNext up, provision the production box:
cd ~/Sites/newsite/trellis
ansible-playbook server.yml -e env=productionDeploy
If all is set up correctly to deploy to staging, we can run these commands:
cd ~/Sites/newsite/trellis
ansible-playbook deploy.yml -e "site=newsite.statenweb.com env=staging" -i hosts/stagingAnd, once this is complete, hit https://newsite.statenweb.com. That should bring up the WordPress installation prompt that provides the next steps to complete the site setup.
If staging is good to go, then we can issue the following commands to deploy to production:
cd ~/Sites/newsite/trellis
ansible-playbook deploy.yml -e "site=newsite.com env=production" -i hosts/productionAnd, like staging, this should also prompt installation steps to complete when hitting https://newsite.com.
Go forth and deploy!
Hopefully, this gives you an answer to a question I had to wrestle with personally and saves you a ton of time and headache in the process. Having stable, secure and scalable server environments that take relatively little effort to spin up has made a world of difference in the way our team works and how we’re able to accommodate our clients’ needs.
While we’re technically done at this point, there are still further steps to take to wrap up your environment fully:
- Add dependencies like plugins, libraries and parent themes to
~/Sites/newsite/composer.jsonand runcomposer updateto grab the latest manifest versions. - Place the theme to
~/Sites/newsite/site/themes/. (Note that any WordPress theme can be used.) - Include any build processes you’d need (e.g. transpiling ES6, compiling SCSS, etc.) in one of the deployment hooks. (See the documentation for Trellis Hooks).
I have also been able to dive into enterprise-level continuous integration and continuous delivery, as well as how to handle premium plugins with Composer by running a custom Composer server, among other things, while incurring no additional cost. Hopefully, those are areas I can touch on in future posts.
Trellis provides a dead simple way to provision WordPress servers. Thanks to Trellis, long gone are the days of manually creating, patching and maintaining servers!
The post I Spun up a Scalable WordPress Server Environment with Trellis, and You Can, Too appeared first on CSS-Tricks.