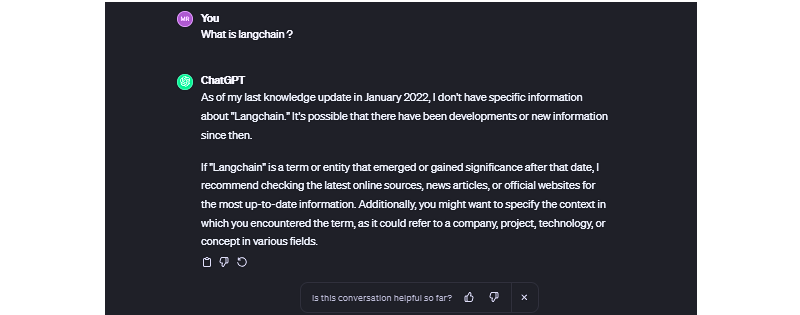
Suppose you ask some AI-based chat app a reasonably simple, straightforward question. Let’s say that app is ChatGPT, and the question you ask is right in its wheelhouse, like, “What is Langchain?” That’s really a softball question, isn’t it? ChatGPT is powered by the same sort of underlying technology, so it ought to ace this answer.
So, you type and eagerly watch the app spit out conversational strings of characters in real-time. But the answer is less than satisfying.
In fact, ask ChatGPT — or any other app powered by language models — any question about anything recent, and you’re bound to get some sort of response along the lines of, “As of my last knowledge update…” It’s like ChatGPT fell asleep Rumplestiltskin-style back in January 2022 and still hasn’t woken up. You know how people say, “You’d have to be living under a rock not to know that”? Well, ChatGPT took up residence beneath a giant chunk of granite two years ago.
While many language models are trained on massive datasets, data is still data, and data becomes stale. You might think of it like Googling “CSS animation,” and the top result is a Smashing Magazine article from 2011. It might still be relevant, but it also might not. The only difference is that we can skim right past those instances in search results while ChatGPT gives us some meandering, unconfident answers we’re stuck with.
There’s also the fact that language models are only as “smart” as the data used to train them. There are many techniques to improve language model’s performance, but what if language models could access real-world facts and data outside their training sets without extensive retraining? In other words, what if we could supplement the model’s existing training with accurate, timely data?
This is exactly what Retrieval Augmented Generation (RAG) does, and the concept is straightforward: let language models fetch relevant knowledge. This could include recent news, research, new statistics, or any new data, really. With RAG, a large language model (LLM) is able to retrieve “fresh” information for more high-quality responses and fewer hallucinations.
But what exactly does RAG make available, and where does it fit in a language chain? We’re going to learn about that and more in this article.
Understanding Semantic Search
Unlike keyword search, which relies on exact word-for-word matching, semantic search interprets a query’s “true meaning” and intent — it goes beyond merely matching keywords to produce more results that bear a relationship to the original query.
For example, a semantic search querying “best budget laptops” would understand that the user is looking for “affordable” laptops without querying for that exact term. The search recognizes the contextual relationships between words.
This works because of text embeddings or mathematical representations of meaning that capture nuances. It’s an interesting process of feeding a query through an embedded model that, in turn, converts the query into a set of numeric vectors that can be used for matching and making associations.

The vectors represent meanings, and there are benefits that come with it, allowing semantic search to perform a number of useful functions, like scrubbing irrelevant words from a query, indexing information for efficiency, and ranking results based on a variety of factors such as relevance.
Special databases optimized for speed and scale are a strict necessity when working with language models because you could be searching through billions of documents. With a semantic search implementation that includes test embedding, storing and querying high-dimensional embedding data is much more efficient, producing quick and efficient evaluations on queries against document vectors across large datasets.
That’s the context we need to start discussing and digging into RAG.
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is based on research produced by the Meta team to advance the natural language processing capabilities of large language models. Meta’s research proposed combining retriever and generator components to make language models more intelligent and accurate for generating text in a human voice and tone, which is also commonly referred to as natural language processing (NLP).
At its core, RAG seamlessly integrates retrieval-based models that fetch external information and generative model skills in producing natural language. RAG models outperform standard language models on knowledge-intensive tasks like answering questions by augmenting them with retrieved information; this also enables more well-informed responses.
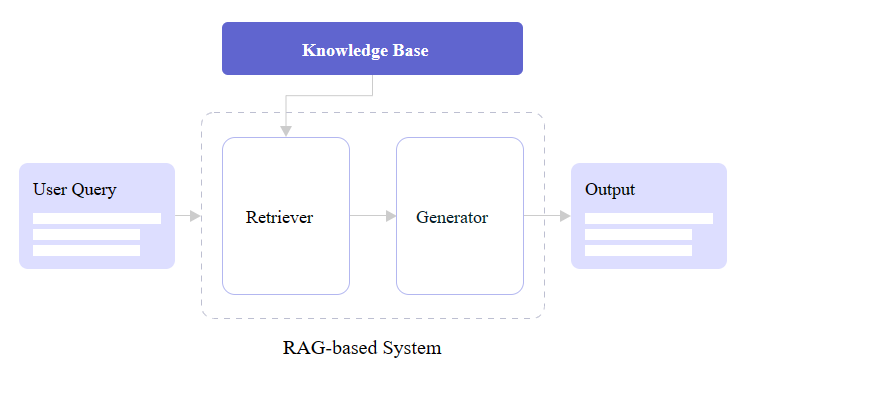
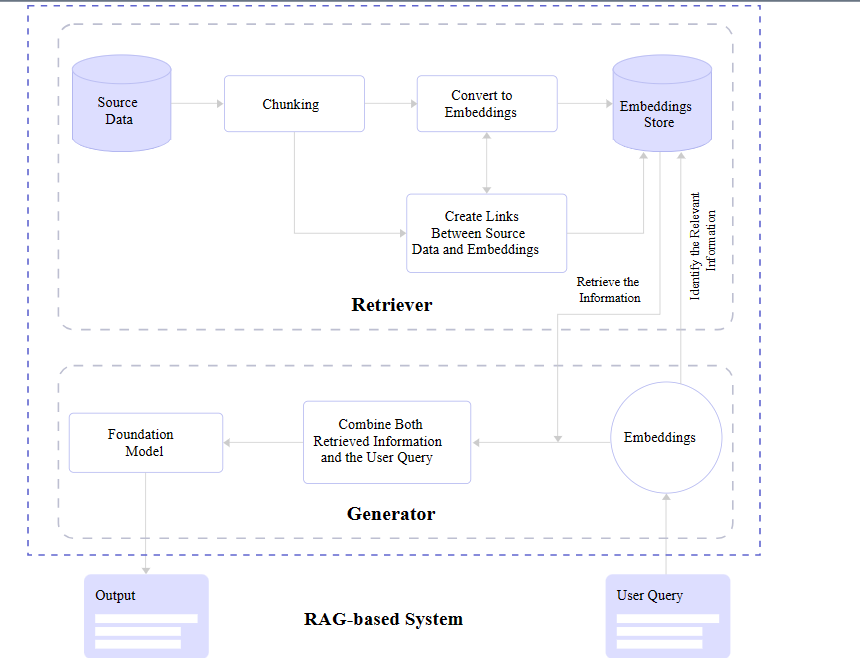
You may notice in the figure above that there are two core RAG components: a retriever and a generator. Let’s zoom in and look at how each one contributes to a RAG architecture.
Retriever
We already covered it briefly, but a retriever module is responsible for finding the most relevant information from a dataset in response to queries and makes that possible with the vectors produced by text embedding. In short, it receives the query and retrieves what it evaluates to be the most accurate information based on a store of semantic search vectors.
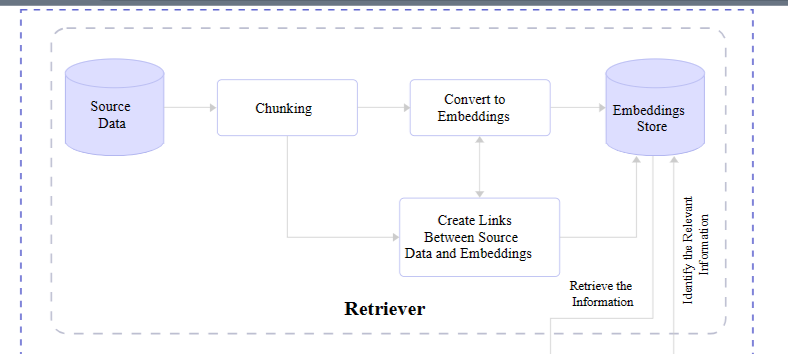
Retrievers are models in and of themselves. But unlike language models, retrievers are not in the business of “training” or machine learning. They are more of an enhancement or an add-on that provides additional context for understanding and features for fetching that information efficiently.
That means there are available options out there for different retrievers. You may not be surprised that OpenAI offers one, given their ubiquity. There’s another one provided by Cohere as well as a slew of smaller options you can find in the Hugging Face community.
Generator
After the retriever finds relevant information, it needs to be passed back to the application and displayed to the user. Or what’s needed is a generator capable of converting the retrieved data into human-readable content.
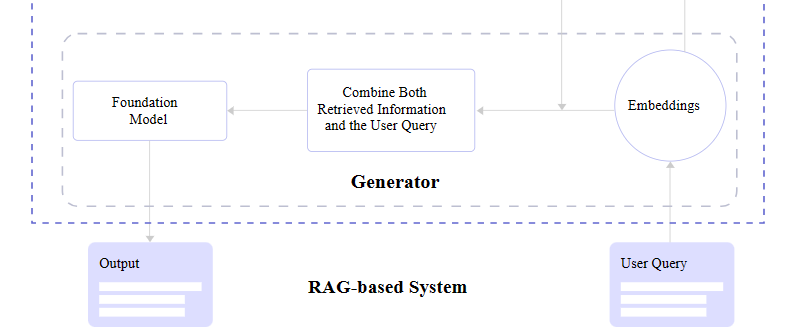
What’s happening behind the scenes is the generator accepts the embeddings it receives from the retriever, mashes them together with the original query, and passes through the trained language model for an NLP pass on the way to becoming generated text.
The entire tail end of that process involving the language model and NLP is a process in its own right and is something I have explained in greater detail in another Smashing Magazine article if you are curious about what happens between the generator and final text output.
RAG Full View
Pulling everything together, a complete RAG flow goes like this:
- A query is made.
- The query is passed to the RAG model.
- The RAG model encodes the query into text embeddings that are compared to a dataset of information.
- The RAG’s retriever decides the most relevant information with its semantic search abilities and converts it into vector embeddings.
- The RAG’s retriever sends the parsed embeddings to the generator.
- The generator accepts the embeddings and combines them with the original query.
- The generator passes its work off to the language model to produce natural-sounding content presented to the user.
LLM Hallucinations And Knowledge Limitations
We opened this article up by describing “hallucinations” in LLMs’ incorrect responses or something along the lines of “I don’t know, but here’s what I do know.” The LLM will “make stuff up” because it simply doesn’t have updated information to respond with.
Let’s revisit the first query we used to kick off this article — “What is LangChain?” — and compare responses from the Vicuna and GPT-4 language models:
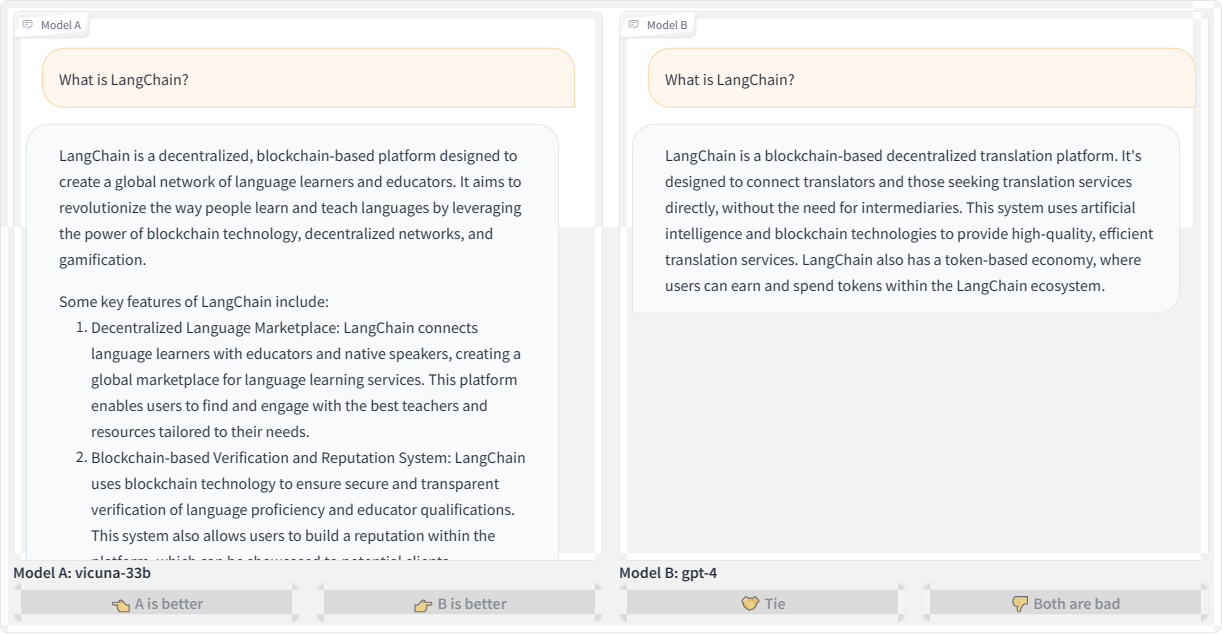
Here’s the transcription for the second query using OpenAI’s GPT-4 for posterity:
“LangChain is a blockchain-based decentralized translation platform. It’s designed to connect translators and those seeking translation services directly without the need for intermediaries. This system uses artificial intelligence and blockchain technologies to provide high-quality, efficient translation services. LangChain also has a token-based economy, where users can earn and spend tokens within the LangChain ecosystem.”
Both Vicuna and GPT-4 refer to LangChain as a blockchain platform. Blockchain is a technology that stores data in a decentralized manner using chained blocks, so the models’ responses sound plausible given the “chain” in the name. However, LangChain is not actually a blockchain-based technology.
This is a prime example demonstrating how LLMs will fabricate responses that may seem believable at first glance but are incorrect. LLMs are designed to predict the next “plausible” tokens in a sequence, whether those are words, subwords, or characters. They don’t inherently understand the full meaning of the text. Even the most advanced models struggle to avoid made-up responses, especially for niche topics they lack knowledge about.
Let’s look at another example by querying: “What is the most preferred framework used by developers for building applications leveraging large language models?”
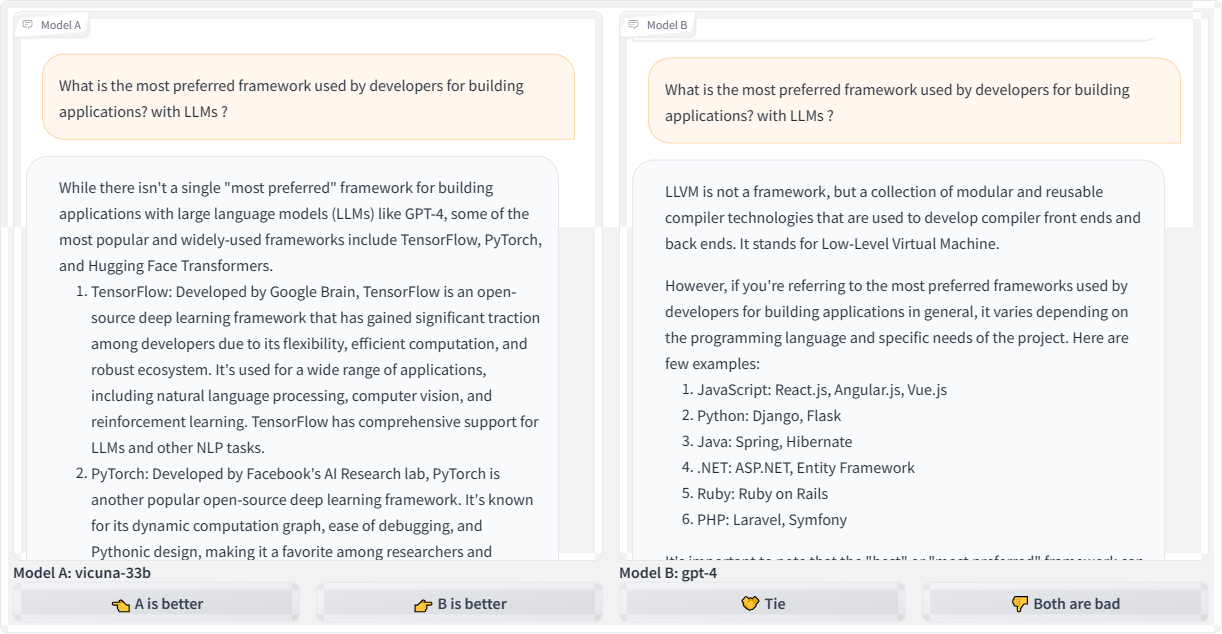
While Vicuna offers a couple of reasonable starting points for answering the question, the frameworks it refers to have limitations for efficiency and scalability in production-level applications that use LLMs. That could quite possibly send a developer down a bad path. And as bad as that is, look at the GPT-4 response that changes topics completely by focusing on LLVM, which has nothing to do with LLMs.
What if we refine the question, but this time querying different language models? This time, we’re asking: “What is the go-to framework developed for developers to seamlessly integrate large language models into their applications, focusing on ease of use and enhanced capabilities?”
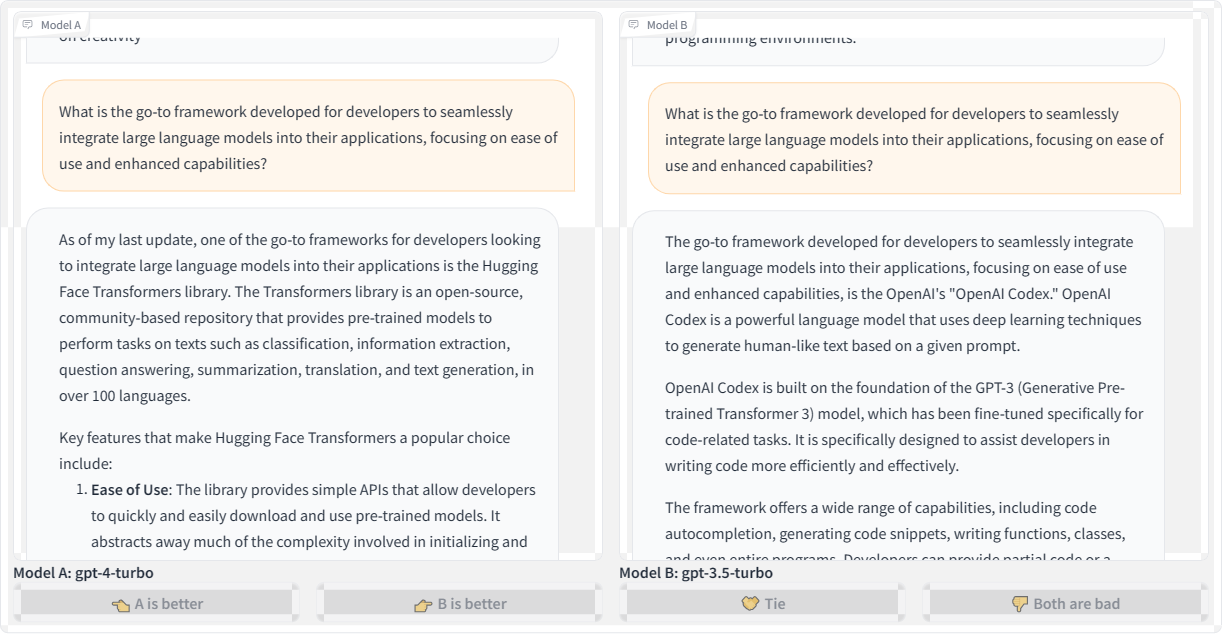
Honestly, I was expecting the responses to refer to some current framework, like LangChain. However, the GPT-4 Turbo model suggests the “Hugging Face” transformer library, which I believe is a great place to experiment with AI development but is not a framework. If anything, it’s a place where you could conceivably find tiny frameworks to play with.
Meanwhile, the GPT-3.5 Turbo model produces a much more confusing response, talking about OpenAI Codex as a framework, then as a language model. Which one is it?
We could continue producing examples of LLM hallucinations and inaccurate responses and have fun with the results all day. We could also spend a lot of time identifying and diagnosing what causes hallucinations. But we’re here to talk about RAG and how to use it to prevent hallucinations from happening in the first place. The Master of Code Global blog has an excellent primer on the causes and types of LLM hallucinations with lots of useful context if you are interested in diving deeper into the diagnoses.
Integrating RAG With Language Models
OK, so we know that LLMs sometimes “hallucinate” answers. We know that hallucinations are often the result of outdated information. We also know that there is this thing called Retrieval Augmented Generation that supplements LLMs with updated information.
But how do we connect RAG and LLMs together?
Now that you have a good understanding of RAG and its benefits, we can dive into how to implement it yourself. This section will provide hands-on examples to show you how to code RAG systems and feed new data into your LLM.
But before jumping right into the code, you’ll need to get a few key things set up:
-
Hugging Face
We’ll use this library in two ways. First, to choose an embedding model from the model hub that we can use to encode our texts, and second, to get an access token so we can download the Llama-2 model. Sign up for a free Hugging Face in preparation for the work we’ll cover in this article.
-
Llama-2
Meta’s powerful LLM will be our generator model. Request access via Meta’s website so we can integrate Llama-2 into our RAG implementation.
-
LlamaIndex
We’ll use this framework to load our data and feed it into Llama-2.
-
Chroma
We’ll use this embedding database for fast vector similarity search and retrieval. This is actually where we can store our index.
With the key tools in place, we can walk through examples for each phase: ingesting data, encoding text, indexing vectors, and so on.
Install The Libraries
We need to install the RAG libraries we identified, which we can do by running the following commands in a new project folder:
# Install essential libraries for our project
!pip install llama-index transformers accelerate bitsandbytes --quiet
!pip install chromadb sentence-transformers pydantic==1.10.11 --quiet
Next, we need to import specific modules from those libraries. There are quite a few that we want, like ChromaVectorStore and HuggingFaceEmbedding for vector indexing and embeddings capabilities, storageContext and chromadb to provide database and storage functionalities, and even more for computations, displaying outputs, loading language models, and so on. This can go in a file named app.py at the root level of your project.
## app.py
## Import necessary libraries
from llama_index import VectorStoreIndex, download_loader, ServiceContext
from llama_index.vector_stores import ChromaVectorStore
from llama_index.storage.storage_context import StorageContext
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index.response.notebook_utils import display_response
import torch
from transformers import BitsAndBytesConfig
from llama_index.prompts import PromptTemplate
from llama_index.llms import HuggingFaceLLM
from IPython.display import Markdown, display
import chromadb
from pathlib import Path
import logging
import sys
Provide Additional Context To The Model
The data we will leverage for our language model is a research paper titled “Enhancing LLM Intelligence with ARM-RAG: Auxiliary Rationale Memory for Retrieval Augmented Generation” (PDF) that covers an advanced retrieval augmentation generation approach to improve problem-solving performance.
We will use the download_loader() module we imported earlier from llama_index to download the PDF file:
PDFReader = download_loader("PDFReader")
loader = PDFReader()
documents = loader.load_data(file=Path('/content/ARM-RAG.pdf'))
Even though this demonstration uses a PDF file as a data source for the model, that is just one way to supply the model with data. For example, there is Arxiv Papers Loader as well as other loaders available in the LlamaIndex Hub. But for this tutorial, we’ll stick with loading from a PDF. That said, I encourage you to try other ingestion methods for practice!
Now, we need to download Llama-2, our open-source text generation model from Meta. If you haven’t already, please set up an account with Meta and have your access token available with read permissions, as this will allow us to download Llama-2 from Hugging Face.
# huggingface api token for downloading llama2
hf_token = "YOUR Access Token"
To fit Llama-2 into constrained memory, like in Google Colab, we’ll configure 4-bit quantization to load the model at a lower precision.
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
Google Colab is where I typically do most of my language model experiments. We’re shrinking the language model down with that last snippet so it’s not too large for Colab to support.
Next, we need to initialize HuggingFaceLLM to set up our model for generating text on the fly:
llm = HuggingFaceLLM(
model_name="meta-llama/Llama-2-7b-chat-hf",
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
query_wrapper_prompt=PromptTemplate("<s> [INST] {query_str} [/INST] "),
context_window=3900,
model_kwargs={"token": hf_token, "quantization_config": quantization_config},
tokenizer_kwargs={"token": hf_token},
device_map="auto",
)
Note that what’s happening here is that we’ve defined our model (Llama-2), but a specific subset of it is designed for a chat UI (Llama-2-Chat). Even though this is what we are using for this article, you can also pick from other text generation models in the Hugging Face hub, such as Neural-chat from Intel.
Compare Outputs
OK, so we have the model loaded and configured. Let’s try it out by asking it questions that it could reasonably answer using the content we provided via the ARM-RAG PDF file to see how the model responds without any context. The following code is for displaying the text output without the PDF providing data to the model for comparison sake:
from IPython.display import HTML, display
# Assuming resp contains the response
resp = llm.complete("What is ARM-RAG?")
# Using HTML with inline CSS for styling (gray color, smaller font size)
html_text = f'<p style="color: #1f77b4; font-size: 14px;"><b>{resp}</b></p>'
Let’s see the response:
display(HTML(html_text))
ARM-RAG (ARM Register-Allocating Generator) is a register allocation algorithm used in compiler design. nobody knows who invented it, but it was first described in a 1995 paper by Mark H. T. Kim and Andrew Y. Chen. The ARM-RAG algorithm is a register-allocating generator, meaning it is a heuristic algorithm that takes a program as input and generates a register allocation plan for it. The goal of the algorithm is to assign registers to variables in a way that minimizes the number of spills (i.e., loads or stores to/from memory) while satisfying all the memory access constraints of the program. The ARM-RAG algorithm works by first partitioning the program into a set of basic blocks, and then iteratively allocating registers to variables within each basic block. The algorithm uses a cost function to evaluate the quality of each allocation, and it selects the allocation with the lowest cost. The cost function takes into account factors such as the distance between the variable and the current register, the distance between the variable and the next allocation, and the number of spills that would be required to allocate the variable. ARM-RAG
Obviously, without any context from the PDF file, the model generates a hallucinated response that describes some unrelated algorithm. To fix this, we need to provide relevant passages from the paper to ground Llama-2’s responses. We’ll encode the document into embeddings and index them for retrieval; then, when we query, we can feed LLama-2 relevant retrieved passages to steer it toward accurate, on-topic responses based on the contents of the PDF file.
First, we need to create a client to interact with our ChromaDB database and a new collection that will hold our vector index.
# create client and a new collection
chroma_client = chromadb.EphemeralClient()
chroma_collection = chroma_client.create_collection("firstcollection")
Then we need to set up the HuggingFaceEmbedding class with the specified model name for embedding the text into vectors:
# Load the embedding model
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
This initializes HuggingFaceEmbedding, passing the name of the pre-trained model we want to use, BAAI/bge-base-en-v1.5. There are other options, of course.
Now, we can set up the vector store and use it to index the embedded document vectors:
# set up ChromaVectorStore and load in data
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context, service_context=service_context
)
This creates a ChromaVectorStore connected to our collection, defines the storage and service contexts, and generates a VectorStoreIndex from the loaded documents using the embedding model. The index is what allows us to quickly find relevant passages for a given query to augment the quality of the model’s response.
We should also establish a way for the model to summarize the data rather than spitting everything out at once. A SummaryIndex offers efficient summarization and retrieval of information:
summary_index = SummaryIndex.from_documents(documents, service_context=service_context)
Earlier, the model hallucinated when we queried it without the added context from the PDF file. Now, let’s ask the same question, this time querying our indexed data:
#Define your query
query="what is ARM-RAG?"
from llama_index.embeddings.base import similarity
query_engine =index.as_query_engine(response_mode="compact")
response = query_engine.query(query)
from IPython.display import HTML, display
# Using HTML with inline CSS for styling (blue color)
html_text = f'<p style="color: #1f77b4; font-size: 14px;"><b>{response}</b></p>'
display(HTML(html_text))
Here’s the output:
Final Response: Based on the context information provided, ARM-RAG is a system that utilizes Neural Information Retrieval to archive reasoning chains derived from solving grade-school math problems. It is an Auxiliary Rationale Memory for Retrieval Augmented Generation, which aims to enhance the problem-solving capabilities of Large Language Models (LLMs). The system surpasses the performance of a baseline system that relies solely on LLMs, demonstrating the potential of ARM-RAG to improve problem-solving capabilities.
Correct! This response is way better than the one we saw earlier — no hallucinations here.
Since we’re using the chat subset of the Llama-2 model, we could have a back-and-forth conversation with the model about the content of the PDF file with follow-up questions. That’s because the indexed data supports NLP.
chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
response = chat_engine.chat("give me real world examples of apps/system i can build leveraging ARM-RAG?")
print(response)
This is the resulting output:
Querying with: What are some real-world examples of apps or systems that can be built leveraging the ARM-RAG framework, which was discussed in our previous conversation?
Based on the context information provided, the ARM-RAG framework can be applied to various real-world examples, including but not limited to:
1. Education: ARM-RAG can be used to develop educational apps that can help students learn and understand complex concepts by generating explanations and examples that can aid in their understanding.
2. Tutoring: ARM-RAG can be applied to tutoring systems that can provide personalized explanations and examples to students, helping them grasp difficult concepts more quickly and effectively.
3. Customer Service: ARM-RAG can be utilized in chatbots or virtual assistants to provide customers with detailed explanations and examples of products or services, enabling them to make informed decisions.
4. Research: ARM-RAG can be used in research environments to generate explanations and examples of complex scientific concepts, enabling researchers to communicate their findings more effectively to a broader audience.
5. Content Creation: ARM-RAG can be applied to content creation systems that can generate explanations and examples of complex topics, such as news articles, blog posts, or social media content, making them more engaging and easier
Try asking more questions! Now that the model has additional context to augment its existing dataset, we can have a more productive — and natural — interaction.
Additional RAG Tooling Options
The whole point of this article is to explain the concept of RAG and demonstrate how it can be used to enhance a language model with accurate and updated data.
Chroma and LlamaIndex were the main components of the demonstrated RAG approach, but there are other tools for integrating RAG with language models. I’ve prepared a table that outlines some popular options you might consider trying with your own experiments and projects.
| RAG |
Type of System |
Capabilities |
Integrations |
Documentation / Repo |
| Weaviate |
Vector Database |
Vector & Generative search |
LlamaIndex, LangChain, Hugging Face, Cohere, OpenAI, etc. |
|
| Pinecone |
Vector Database |
Vector search, NER-Powered search, Long-term memory |
OpenAI, LangChain, Cohere, Databricks
|
|
| txtai |
Embeddings Database |
Semantic graph & search, Conversational search |
Hugging face models |
|
| Qdrant |
Vector Database |
Similarity image search, Semantic search, Recommendations |
LangChain, LlamaIndex, DocArray, Haystack, txtai, FiftyOne, Cohere, Jina Embeddings, OpenAI
|
|
| Haystack |
Framework |
QA, Table QA, Document search, Evaluation |
Elasticsearch, Pinecone, Qdrant, Weaviate, vLLM, Cohere
|
|
| Ragchain |
Framework |
Reranking, OCR loaders |
Hugging Face, OpenAI, Chroma, Pinecone |
|
| metal |
Vector Database |
Clustering, Semantic search, QA |
LangChain, LlamaIndex
|
|
Conclusion
In this article, we examined examples of language models producing “hallucinated” responses to queries as well as possible causes of those hallucinations. At the end of the day, a language model’s responses are only as good as the data it provided, and as we’ve seen, even the most widely used models consist of outdated information. And rather than admit defeat, the language model spits out confident guesses that could be misconstrued as accurate information.
Retrieval Augmented Generation is one possible cure for hallucinations.
By embedding text vectors pulled from additional sources of data, a language model’s existing dataset is augmented with not only new information but the ability to query it more effectively with a semantic search that helps the model more broadly interpret the meaning of a query.
We did this by registering a PDF file with the model that contains content the model could use when it receives a query on a particular subject, in this case, “Enhancing LLM Intelligence with ARM-RAG: Auxiliary Rationale Memory for Retrieval Augmented Generation.”
This, of course, was a rather simple and contrived example. I wanted to focus on the concept of RAG more than its capabilities and stuck with a single source of new context around a single, specific subject so that we could easily compare the model’s responses before and after implementing RAG.
That said, there are some good next steps you could take to level up your understanding:
- Consider using high-quality data and embedding models for better RAG performance.
-
Evaluate the model you use by checking Vectara’s hallucination leaderboard and consider using their model instead. The quality of the model is essential, and referencing the leaderboard can help you avoid models known to hallucinate more often than others.
-
Try refining your retriever and generator to improve results.
My previous articles on LLM concepts and summarizing chat conversations are also available to help provide even more context about the components we worked with in this article and how they are used to produce high-quality responses.
References