An Introductory Guide On How To Do Web Scraping: Extracting Data From Your Website

Web scraping is a great solution for those looking to access structured web data from websites containing large amounts of invaluable information.
Also known as web extraction, web scraping is a tool that helps you to gain information on products, contacts, and a lot more, even when a website doesn’t have an API (application programming interface), or grants limited access to its data.
Web scraping offers a faster, more practical solution for extracting data from a website, instead of having to use the same format as the website in question, or even just copying and pasting information manually.
What is web scraping?
Web scraping is the process of gathering structured data into a spreadsheet or other file, but in an automated way. In the same way that a person can manually copy and paste information from a website into a document, web scraping performs the same function, just on a different scale. Web scraping also performs this task incredibly efficiently, extracting up to billions of data points through intelligent automation.
It is often used by businesses and individuals looking to make use of the huge amounts of information available on the web, implementing web scraping into their data management scheme. This information can be mined to help a company to make smarter, better, informed decisions.
Data scraping is particularly valuable, in fact, for companies looking to gather data on specific, niche topics. This data can then be utilized in your marketing strategy, where you might be considering the best niches for affiliate marketing.
Web scraping can be used for more than business intelligence however, as it can reveal insights into pricing and price comparison sites, Google Shopping related metrics where product data from an e-commerce site is sent to another online vendor, and can even help find sales leads and conduct market research. It has many benefits and many uses, though it is not necessarily always a simple task.
This is because websites can often be very diverse, coming in several different formats, shapes and sizes. As a result, you will find multiple different kinds of web scrapers, which all offer different functions and features. This is similar to the way in which there are multiple different kinds of mobile data collection apps to pick from.
Is web scraping a crime?
Web scraping is not illegal when it is used to mine public web data. However, it is important that you follow the prescribed rules, and avoid scraping information that is not available to the public. Scraping this data is illegal, and has become a rising crime with multiple recent cases of illegal web extraction occurring.
Though web scraping is a tool with many valuable features, it can be abused. A very common abuse of web scraping is through email harvesting. Scraping data from websites and social media can enable a person to harvest people’s email addresses, which can then be sold on to third parties and spammers for a sum. Harvesting data with commercial intent is illegal.
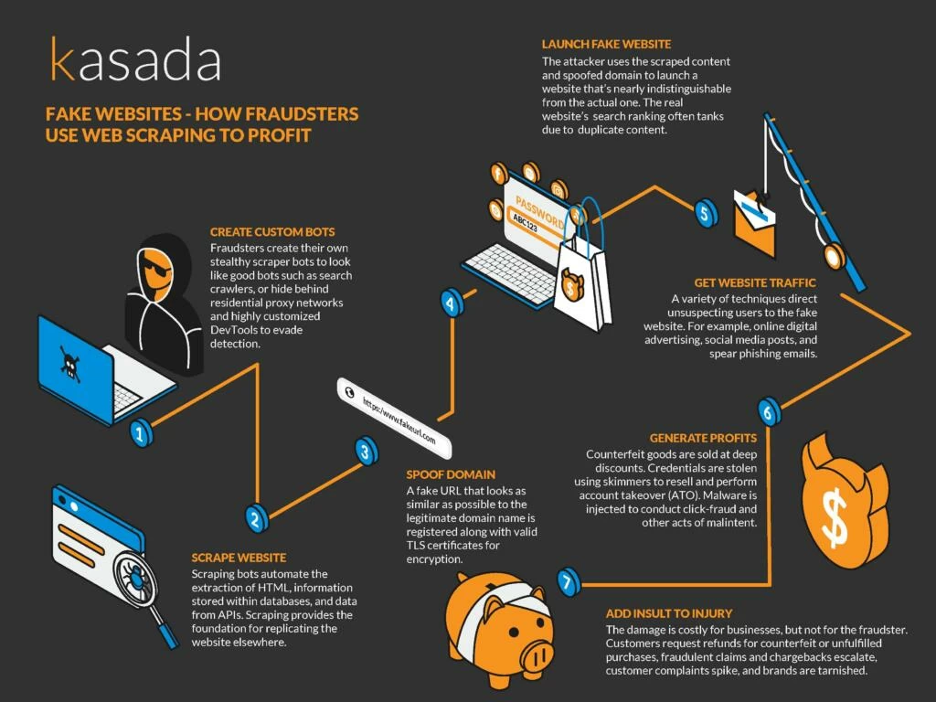
It is important that you remain aware of the darker side of web scraping and the importance of only harvesting data, or even emails acquired through an email finder, that is publicly available.
This also helps demonstrate why webpage defacement monitoring on your own company websites and personal blogs is so important.
How do web scrapers work?
Whether you want to learn to perform data scraping yourself, or are looking to learn more about it before you outsource the job to a data extraction specialist, it’s really important that you understand how it works, and the difference between web crawling and web scraping.
Web scraping works by first choosing the URLs you want to load before you begin scraping. You need to load the whole HTML code of that page in order to continue. If you outsource to a specialist or learn to do it yourself, you can go as far as loading the entire website, including all the Javascript and CSS. However, this isn’t necessary to perform web scraping, so don’t worry about it too much, especially if you are a beginner.
Then, the scraper extracts all the data on the page. However, you can choose what specific data you want to extract. This is performed when you only need specific information, and aren’t interested in the rest of the data on the page you are scraping.
Then, all the data is outputted. This is done using the format that the web scraper has chosen, depending on what format will be most useful to the individual. Usually, data is output as an Excel spreadsheet or a CSV file, but more advanced web scrapers are also able to output data in other formats such as an API or JSON file.
For more on learning to manage and organize your data: DataBricks Apache Hive articles.
What about web crawling?
Web scraping and web crawling go hand in hand. Web crawling comes before web scraping, and involves artificial intelligence that searches the internet to look for content, indexing it.
This process finds the relevant websites and URLs that are then passed onto the web scraper, who uses them to mine information.
Web scrapers are specialized tools, designed to extract data from websites. There are four main types of scrapers, and they differ widely from one another.

Types of web scrapers
Broadly speaking, web scrapers can be distinguished by placing them into four categories:
Category One: browser extension vs software
Generally speaking, web scrapers come in one of two forms, browser extensions and computer software. Browser extensions are simpler to run and are integrated directly into your browser. Like apps, they are programs that can be added to your browser (such as Firefox or Google Chrome). Some of the other best chrome extensions also include messaging extensions and ad blockers.
However, these extensions are limited in that they ‘live’ inside of your browser. This means that advanced features are usually impossible to implement. On the other hand, scraping software can be installed onto your computer with a simple download. They enable more advanced features (not limited by what your browser can do), making up for the fact that they are a bit less convenient than browser extensions.
Category two: self-built vs pre-built
Anyone can build their own web scraper. However, even in the implementation of tools that help you build a web scraper, there is a certain amount of coding knowledge needed. The more features you want to add to your scraper, the more knowledge you will need to have, as complexity increases accordingly.
On the other hand, you might want to opt for a pre-built web scraper that you can download and start using straight away. Some will offer advanced features (already built-in) such as Google Sheets Exports and more. This is a good option for those who have little familiarity with coding. If this seems enticing, consider learning more from databricks’ Introduction of hadoop to get you started.
Category three: User Interface
A user interface (UI) can vary depending on the web scraper. Some web scrapers have a full on UI, with a fully rendered website that users can click on and scrape. If you have little technical knowledge of coding and how scraping works, then this is a good place to begin.
The alternative – a user interface with a minimalistic UI and command line – might feel less intuitive and more confusing to a beginner, and might be worth avoiding if you are only just starting out.
Category four: Local vs Cloud
This is all about where your web scraper is doing its job from.
A local scraper runs using resources from your own computer and the internet. This can result in your computer becoming quite slow whilst it is scraping data, especially if it has a high usage of CPU or RAM. This can make your computer pretty much useless for other tasks whilst it is being used to scrape.
On the other hand, cloud-based web scrapers run using off-site servers provided by companies that develop scrapers. This gives you the ability to use your computer freely as its resources are not taken up by web scraping. You simply get notified when the data harvesting has completed.
How to do web scraping
Although the process, in itself, is fairly straightforward, it becomes complicated the minute your project grows to any significant size. As a result, it is often easier to outsource the job to a company of professional web scrapers. However, it is still interesting to understand the process of DIY web scraping, alongside learning about other forms of data collection.
Firstly, you need to identify the target website you are interested in scraping (a web crawler can help you do this). Let’s take websites for free stock videos as an example.
Then, collect all the URLs of the pages that hold the data you are looking to extract, namely on visual stock content.
Once you’ve done that, send a request to these URLs asking to be granted access to the HTML of the pages in question.
Then, once this is completed, use locators to find the data within the HTML.
Lastly, save said data in a CSV or JSON file, or in any other form of structured format that suits you. And just like that, you have a large amount of data on stock videos, all saved in one place.
If this seems like a tricky task, then an open-source web scraping data tool might be the right step forward for you. Or at the very least, a HDFS file system (what is HDFS in hadoop).
Conclusions
Whether or not you plan to implement data scraping yourself or outsource to a specialist, it is important that you understand the process – it’s only going to grow in importance and popularity as more companies seek to make the most of the data that is available on the internet.
Without this valuable data, a company can never hope to make sense of a customer’s ecommerce journey, thus serving a vital purpose within a retailer’s repertoire of tools.
The post An Introductory Guide On How To Do Web Scraping: Extracting Data From Your Website appeared first on noupe.
