Every week users submit a lot of interesting stuff on our sister site Webdesigner News, highlighting great content from around the web that can be of interest to web designers.
The best way to keep track of all the great stories and news being posted is simply to check out the Webdesigner News site, however, in case you missed some here’s a quick and useful compilation of the most popular designer news that we curated from the past week.
Note that this is only a very small selection of the links that were posted, so don’t miss out and subscribe to our newsletter and follow the site daily for all the news.
Instagram Mockup 2020
UI Inspiration: 20 Examples of Dashboard Designs
Animockup – Free Animated Mockup Maker
Prettier 2.0 – Opinionated JavaScript Formatter
The UX Writing Starter-Kit
I Don’t Care What Google or Apple or Whoever Did
Free Signature Fonts
Top UI/UX Design Trends for Mobile Apps in 2020
Problem Solving 101: Thinking in Systems
5 Best SaaS Bootstrap Template for 2020
The Web We Lost: Luke Dorny Redesign
Testing New Product Ideas with Landing Pages
How to Plan a Website Redesign When You Want to Scale
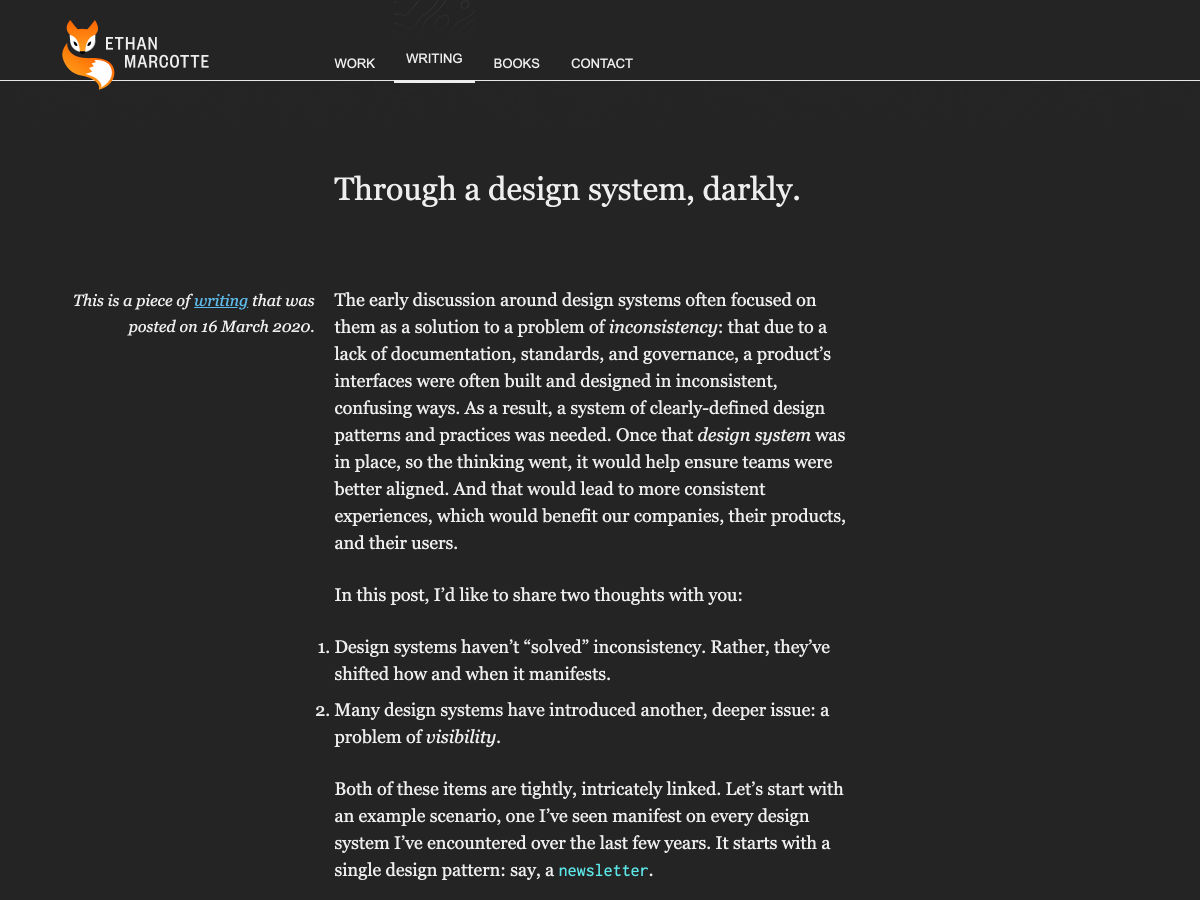
Through a Design System, Darkly
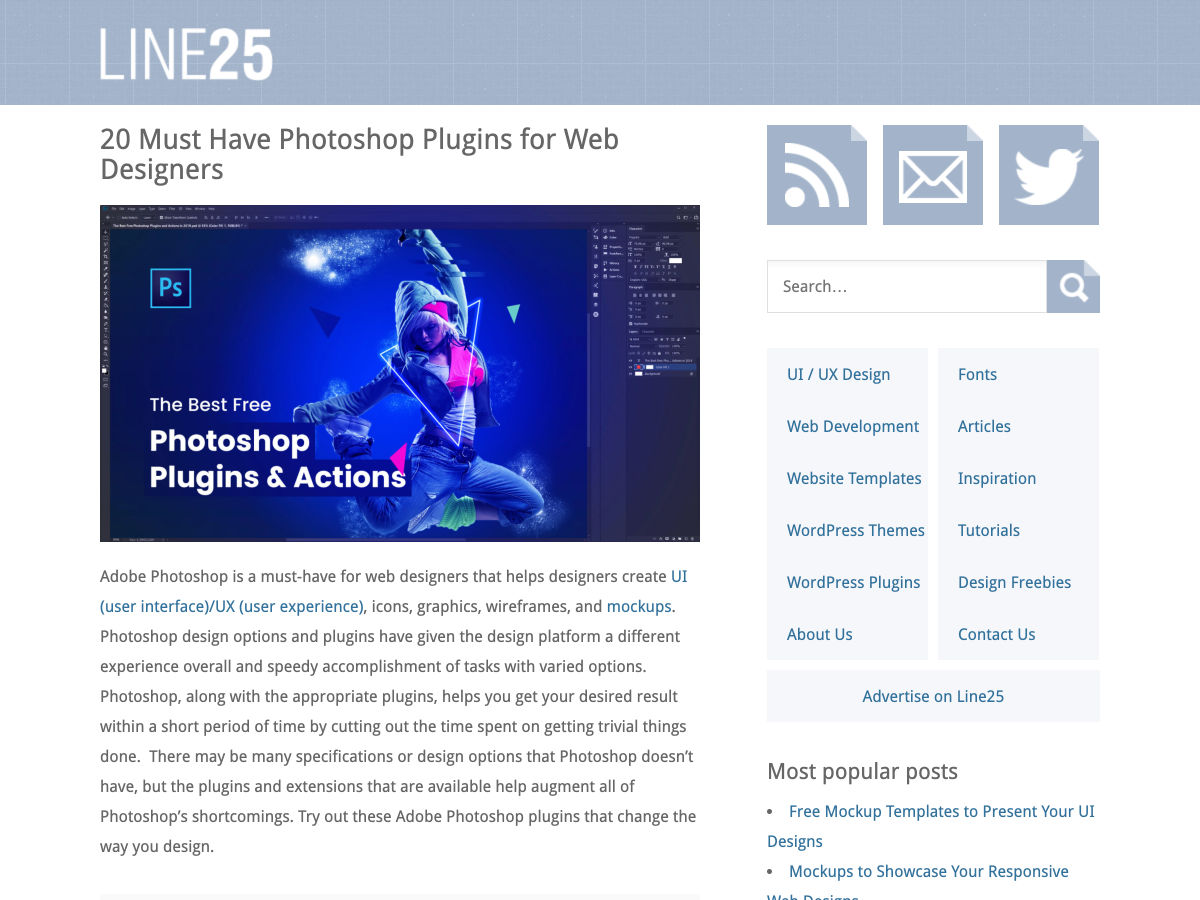
20 Must Have Photoshop Plugins for Web Designers
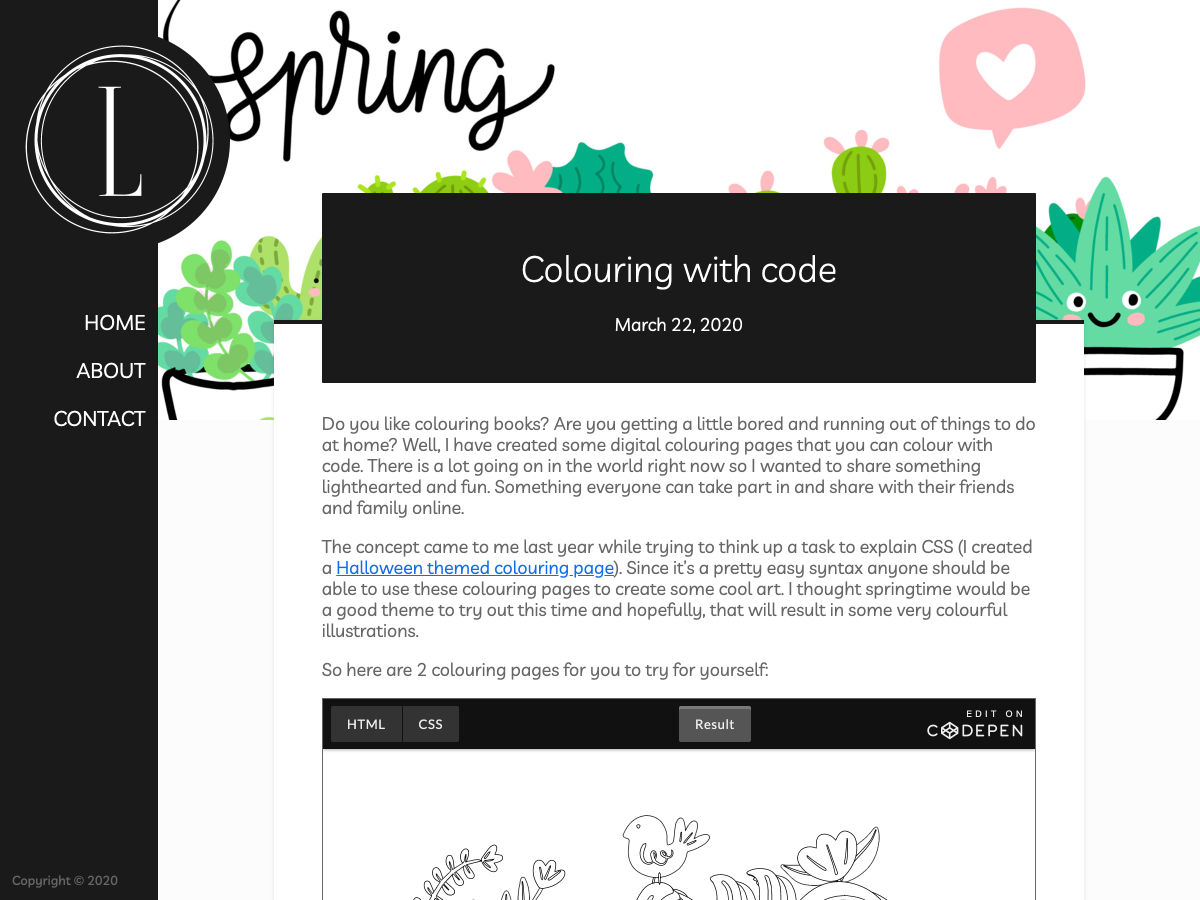
Colouring with Code
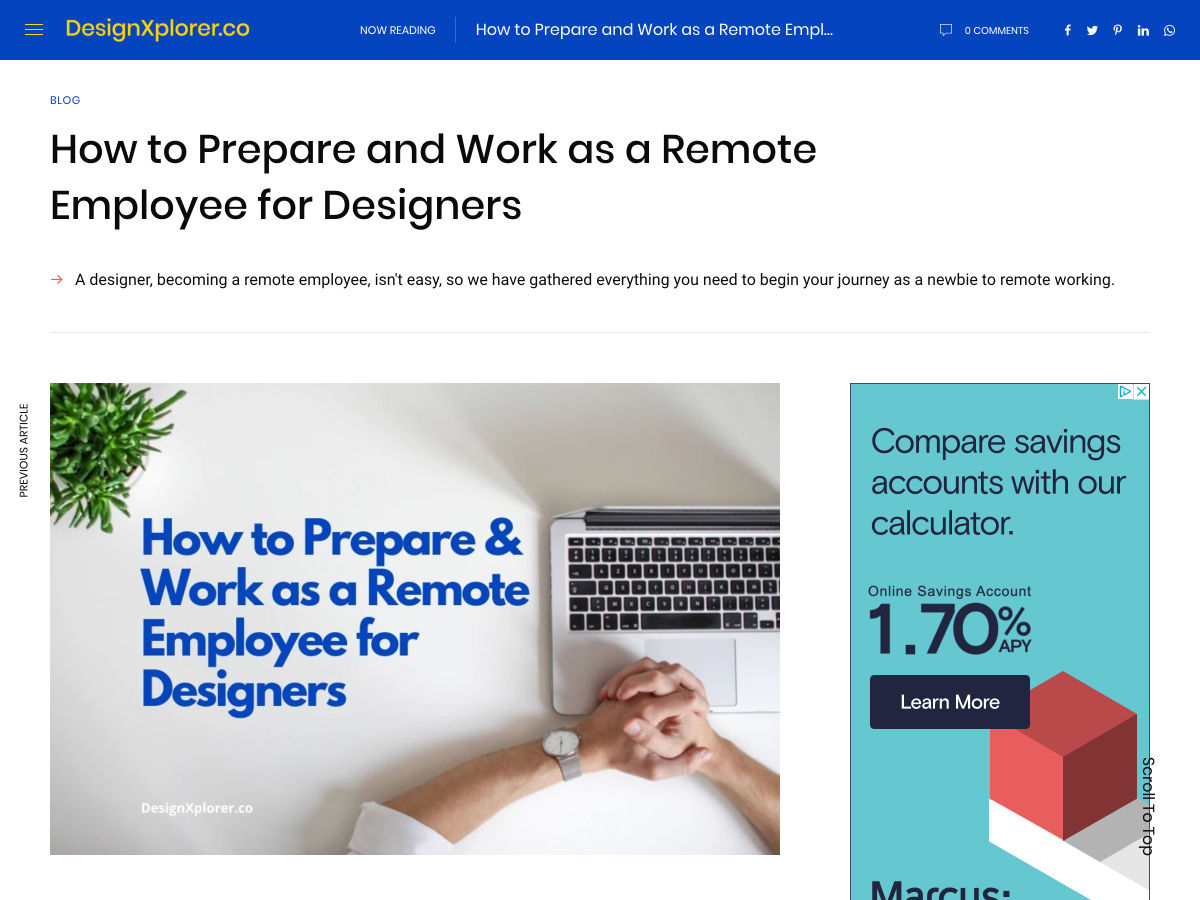
Designer: How to Prepare and Work as a Remote Employee
Polaroid is Back (again, Sort of) with a Rebrand and New Camera
15 Best Futuristic Fonts for Designers
Emergency Website Kit
Our Essential List of Free Software for Remote Work
6 Neuromarketing Tricks for your Visual Content
Documenting the Humane Design Movement
Designer’s Work Music Fix
Why Design Systems Fail, and How to Make Them Work
Want more? No problem! Keep track of top design news from around the web with Webdesigner News.
Scott Turner, who has an entire blog “Exploring procedural generation and display of fantasy maps”, gets into why vector graphics seems on these surface why it would be bad for the look of a pencil stroke:
Something like this pencil stroke would require many tens of thousands of different elements. Basically each little blob of gray in that image would be separately defined.
Nada Rifki demonstrates the scroll-snap-type and scroll-snap-alignCSS properties. I like that the demo shows that the items in the scrolling container can be different sizes. It is the edges of those children that matter, not some fixed snapping distance.
Here’s an outstanding idea from Max Böck. He’s created a boilerplate project for building websites that fit within a single HTTP request. This is extremely important for websites that contain critical information for public safety. As Max writes:
In cases of emergency, many organizations need a quick way to publish critical information. But exisiting (CMS) websites are often unable to handle sudden spikes in traffic.
What’s so special about this boilerplate? Well, it does smart stuff like:
provides one-click deployment via Netlify to get off the ground quickly
The example website that Max built with this boilerplate is shockingly fast and I would go one step further to argue that all websites should feel as fast as this, not just websites that are useful in an emergency.
Remember Tabletop.js? We just covered it a little bit ago in this same exact context: building editable websites. It’s a tool that turns a Google Sheet into an API, that you as a developer can hit for data when building a website. In that last article, we used that API on the client side, meaning JavaScript needed to run on every single page view, hit that URL for the data, and build the page. That might be OK in some circumstances, but let’s do it one better. Let’s hit the API during the build step so that the content is built into the HTML directly. This will be far faster and more resilient.
The situation
As a developer, you might have had to work with clients who keep bugging you with unending revisions on content, sometimes, even after months of building the site. That can be frustrating as it keeps pulling you back, preventing you from doing more productive work.
We’re going to give them the keys to updating content themselves using a tool they are probably already familiar with: Google Sheets.
A new tool
In the last article, we introduced the concept of using Google Sheets with Tabletop.js. Now let’s introduce a new tool to this party: Eleventy.
We’ll be using Eleventy (a static site generator) because we want the site to be rendered as a pure static site without having to ship all of the under workings of the site in the client side JavaScript. We’ll be pulling the content from the API at build time and having Eleventy create a minified index.html that we’ll push to the server for the production website. By being static, this allows the page to load faster and is better for security reasons.
The spreadsheet
We’ll be using a demo I built, with its repo and Google Sheet to demonstrate how to replicate something similar in your own projects. First, we’ll need a Google Sheet which will be our data store.
Open a new spreadsheet and enter your own values in the columns just like mine. The first cell of each column is the reference that’ll be used later in our JavaScript, and the second cell is the actual content that gets displayed.
In the first column, “header” is the reference name and “Please edit me!” is the actual content in the first column.
Next up, we’ll publish the data to the web by clicking on File ? Publish to the web in the menu bar.
A link will be provided, but it’s technically useless to us, so we can ignore it. The important thing is that the spreadsheet(and its data) is now publicly accessible so we can fetch it for our app.
Take note that we’ll need the unique ID of the sheet from its URL as we go on.
Node is required to continue, so be sure that’s installed. If you want to cut through the process of installing all of thedependencies for this work, you can fork or download my repo and run:
npm install
Run this command next — I’ll explain why it’s important in a bit:
npm run seed
Then to run it locally:
npm run dev
Alright, let’s go into src/site/_data/prod/sheet.js. This is where we’re going to pull in data from the GoogleSheet, then turn it into an object we can easily use, and finally convert the JavaScript object back to JSON format. The JSON is stored locally for development so we don’t need to hit the API every time.
Here’s the code we want in there. Again, be sure to change the variable sheetID to the unique ID of your own sheet.
module.exports = () => {
return new Promise((resolve, reject) => {
console.log(`Requesting content from ${googleSheetUrl}`);
axios.get(googleSheetUrl)
.then(response => {
// massage the data from the Google Sheets API into
// a shape that will more convenient for us in our SSG.
var data = {
"content": []
};
response.data.feed.entry.forEach(item => {
data.content.push({
"header": item.gsx$header.$t,
"header2": item.gsx$header2.$t,
"body": item.gsx$body.$t,
"body2": item.gsx$body2.$t,
"body3": item.gsx$body3.$t,
"body4": item.gsx$body4.$t,
"body5": item.gsx$body5.$t,
"body6": item.gsx$body6.$t,
"body7": item.gsx$body7.$t,
"body8": item.gsx$body8.$t,
"body9": item.gsx$body9.$t,
"body10": item.gsx$body10.$t,
"body11": item.gsx$body11.$t,
"body12": item.gsx$body12.$t,
"body13": item.gsx$body13.$t,
"body14": item.gsx$body14.$t,
"body15": item.gsx$body15.$t,
"body16": item.gsx$body16.$t,
"body17": item.gsx$body17.$t,
})
});
// stash the data locally for developing without
// needing to hit the API each time.
seed(JSON.stringify(data), `${__dirname}/../dev/sheet.json`);
// resolve the promise and return the data
resolve(data);
})
// uh-oh. Handle any errrors we might encounter
.catch(error => {
console.log('Error :', error);
reject(error);
});
})
}
In module.exports, there’s a promise that’ll resolve our data or throw errors when necessary. You’ll notice that I’m using a axios to fetch the data from the spreadsheet. I like the it handles status error codes by rejecting the promise automatically, unlike something like Fetch that requires monitoring error codes manually.
I created a data object in there with a content array in it. Feel free to change the structure of the object, depending on what the spreadsheet looks like.
We’re using the forEach() method to loop through each spreadsheet column while equating it with the corresponding name we want to allocate to it, while pushing all of these into the data object as content.
Remember that seed command from earlier? We’re using seed to transform what’s in the data object to JSON by way of JSON.stringify, which is then sent to src/site/_data/dev/sheet.json.
Yes! Now have data in a format we can use with any templating engine, like Nunjucks, to manipulate it. But, we’re focusing on content in this project, so we’ll be using the index.md template format to communicate the data stored in the project.
For example, here’s how it looks to pull item.header through a for loop statement:
<div class="listing">
{%- for item in sheet.content -%}
<h1>{{ item.header }} </h1>
{%- endfor -%}
</div>
If you’re using Nunjucks, or any other templating engine, you’ll have to pull the data accordingly.
Finally, let’s build this out:
npm run build
Note that you’ll want a dist folder in the project where the build process can send the compiled assets.
But that’s not all! If we were to edit the Google Sheet, we won’t see anything update on our site. That’s where Zapier comes in. We can “zap” Google sheet and Netlify so that an update to the Google Sheet triggers a deployment from Netlify.
Assuming you have a Zapier account up and running, we can create the zap by granting permissions for Google and Netlify to talk to one another, then adding triggers.
The recipe we’re looking for? We’re connecting Google Sheets to Netlify so that when a “new or updated sheet row” takes place, Netlify starts a deploy. It’s truly a set-it-and-forget-it sort of deal.
Yay, there we go! We have a performant static site that takes its data from Google Sheets and deploys automatically when updates are made to the sheet.
I, Dave Rupert, a person who cares about web performance, a person who reads web performance blogs, a person who spends lots of hours trying to keep up on best practices, a person who co-hosts a weekly podcast about making websites and speak with web performance professionals… somehow goofed and added 33 SECONDS to their page load.
This stuff is hard even when you care a lot. The 33 seconds came from font preloading rather than the one-line wonder of font-display.
I also care about making fast websites, but mine aren’t winning any speed awards because I’ll take practical and maintainable over peak performance any day. (Sorry, world)
According to the WHO, there are 416,686 confirmed cases worldwide for now. People are losing their lives. Healthcare professionals are working incredibly hard to deal with the situation, and we need to do our part, and stay in our homes.
Due to the recent epidemic of Coronavirus, the economy has also taken a huge hit. Most businesses are closed or having hard times. Some of us, the lucky ones, can work from home and use the tools that have been provided to us to get the most out of our work and minimize the damage.
Here are some of the remote work tools that you can use:
Zoom is a video conferencing tool that allows you to connect with your team easily. It’s a great tool to connect to your team and have meetings. It’s now free for K-12 schools.
Data collection tool with many widgets, integrations, payment processing and ability to assign forms to your teammates. If you are fighting against the Coronavirus, you get a free, unlimited and HIPAA compliant account.
Airtable is a cloud collaboration service that is widely used. And now, the Airtable Pro plan is completely free without a time limit for any non-political humanitarian groups working on COVID-19 relief efforts.
Free Covid-19 Care Response solution for Healthcare systems. It’s for emergency response teams, call centers, and care management teams who are affected by Covid-19.
Online work scheduling tool to help remote workers stay connected. Zoom and GoToMeeting integrations used to be paid, but now they are free until June 30. Also, premium plans are now free for teams working directly on Covid-19.
Collaborative work management platform. They offer 6 months free access to Professional Edition for the new customers. Also, if you are a current customer, you can add unlimited collaborators.
Remotely apps are free until July 1, 2020. There are 11 apps in total, which includes apps for storage, project management, online meetings, and presentations.
Free Xfinity WiFi, the hotspots are available to everyone for COVID-19, not just the Xfinity subscribers. Network name is: “xfinity wifi”. You can find a hotspot near you on their website.
Secure file-sharing and collaboration platform for 3 months. You’ll get the Business plan which has unlimited storage, advanced user and security reporting.
Enhanced Go-Live streaming service limit is upped to 50 from 10. Go Live is free to use and enables you to screen share apps from your computer or privately stream while your team can watch from any device.
Git was released almost 15 years ago. In that time it has gone from underdog to unbeaten champion, git init is often the first command run on a new project. It is undoubtedly an important tool that many of us use on a daily basis… and yet it is often seen as magic: brilliant, but scary.
There’s been a lot written about getting started with git, understanding how git works under the hood or techniques for better branching strategies. In this article, we will specifically target the stuff that just makes your life better in a small way.
Finding Your Old Socks
The whole point of git is to be able to save your work, to switch context and do something else. It could be to backup the code for the future, or to be able to make progress on a few different features asynchronously. It would be awful to have to throw out v2 just because there was a bug in v1, it would be equally a shame to have files named like v1_final_bug_fixed which notoriously become an impossible mess.
We know life is easier, to some extent, with our updates neatly compartmentalised into git branches that can be shared with other team members. However, I’m sure you can agree, there are often times when you’ve context switched and when you go back it’s impossible to find the right branch. Was it ever committed? Maybe it was stashed? Maybe it wasn’t committed and now the work is in the wrong branch and everything is going awful and I am awful at my job! We’ve all been there.
Sort Branches By Date
My first attempt at figuring out how to find lost work, in a short blog post titled “How to find the branch you lost in git” was to sort the branches by date. This outputs every single branch you’ve got locally beginning with the one most recently committed to. It’s not fancy or surprising but it has helped me many times.
# To sort branches by commit date
git branch --sort=-committerdate
Previous Branch
What can you do if you didn’t commit, switched branch then wanted to get back to it? You could probably work out frorm the branch list anyway, if you’ve some idea of the branch name. But what if it wasn’t a branch, if it was a “detached HEAD”, a specific commit.
It turns out there is a way to do this with ease:
# Checkout previous branch
git checkout -
The - acts as a shorthand for @{-1} which is a syntax you can use for going back any given amount of checkouts. So if, for example, you had checked out branch feature/thing-a then feature/thing-b then bugfix/thing-c, you can use @{-2} to get back to feature/thing-a.
# Checkout branch N number of checkouts ago
git checkout @{-N}
Show Information About All Branches
If you are looking for a way to see what the last commit in each branch was, you can use option flags v to show a list of all branches with the last commit ID and message from each. If you do it twice (vv) then it will also show the upstream remote branch that it is linked to.
# List branches along with commit ID, commit message and remote
git branch -vv
That One File
We’ve all done it: Somehow, a single file was left in the wrong branch. Do you need to redo all of your work, or copy and paste between the two branches? Nope, thankfully there’s a way to do it.
It’s a bit odd, especially given git checkout - goes back a previous branch; if you use -- after a branch name on checkout then it will let you specific the specific file you’re looking for. It’s not something you would guess, but really handy once you know it.
In a tweet, Tomasz ?akomy mentioned about reducing the output of git status using -sb flags and said, “I’ve been using git for YEARS and nobody told me about this.” This isn’t strictly about finding lost files, but there’s cases where simplifying the output could make it easier to see what’s been changed.
Most git commands have flags like this so it’s always worth looking into how you can use them to customise your workflow!
# Usually we would use git status to check what files have changed
git status
# Outputs:
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
Untracked files:
(use "git add <file>..." to include in what will be committed)
another-file
my-new-file
# Using the flags -sb we can shorten the output
git status -sb
# Outputs:
## master
M README.md
?? another-file
?? my-new-file
See Everything That Has Happened
There are times when something goes completely wrong — such as accidentally discarding staged changes before commiting them. When git log isn’t enough to get back to what you were last doing and none of the above tips are helpful, then there’s git reflog.
Everything you do in git that changes where HEAD@{} points to (such as push/pull/branch/checkout/commit) will update the reference log so it essentially acts as a history of everything you’ve done no matter which branch you’re on. This contrasts with git log which is everything that has changed over time for the particular branch.
With the commit ID, you are able to do git show to see the change and if it’s definitely the one you want you can use git checkout or even select a specific file as shown above.
# See the reference log of your activity
git reflog --all
# Look at the HEAD at given point from reflog
git show HEAD@{2}
# Checkout the HEAD, to get back to that point
git checkout HEAD@{2}
Staged Files That Were Never Commited
In the extreme case that git reflog is unable to help you get your files back (e.g. if you ran a hard reset with staged files), there’s one more trick up your sleeve. Every change is stored in .git/objects which on an active project would be full of files and impossible to decipher. There is, however, a git command called git fsck which is used to verify integrity (check for corrupt files) within a repository. We are able to use this command with the --lost-found flag to find all files that are not related to a commit; these files are called a “dangling blob”.
It will also find “dangling trees” and “dangling commits” — you can use --dangling if you want but --lost-found has the advantage that it extracts all of the appropriate files into a folder .git/lost-found. On an active project, it’s likely you will have a lot of these dangling files without even knowing about it; git has a garbage cleanup command that runs regularly to get rid of them.
So, by using --lost-found, you’re then able to list the files and see the time/date they were made which makes it a lot easier to see the files you’re looking for. Note that each individual file will still be an individual file (you cannot use checkout) and all files will have unrecognisable names (a hash) so you will need to copy the files you want.
# This will find any change that was staged but is not attached to the git tree
git fsck --lost-found
# See the dates of the files
ls -lah .git/lost-found/other/
# Copy the relevant files to where you want them, for example:
cp .git/lost-found/other/73f60804ac20d5e417783a324517eba600976d30 index.html
Git As A Team
Using Git as a single user is one thing but when you’re on a team of people — usually with a mix of backgrounds and technologies — Git can become both a blessing and a curse. It can be powerful for sharing the same codebase, getting code reviews, and seeing progress of the whole team. But at the same time, everyone needs to have a shared understanding of how the team intends to use it. Whether it is branch naming conventions, how you structure a commit message or exactly which files are committed, it’s essential to have good communication and talk about how you will all use the tool.
It’s always important to consider how easy it is to on-board a new developer, what would happen if they began committing without knowing some of the agreed principles and conventions? It wouldn’t be the end of the world, but it would likely cause some confusion and take time to get things back to the agreed approach.
This section has some tips and tricks for getting the repository itself to know the conventions, to automate and declare as much as possible. In the ideal case, any new contributor would almost straight away be working the same way as the rest of the team.
Same Line Endings
By default, Windows uses DOS line endings rn (CRLF) while Mac and Linux both use UNIX line endings n (LF) and really old versions of Mac used to use r (CR). So as a team grows, it becomes more likely that mismatched line endings will become a problem. Usually, these are an inconvenience; they (probably) won’t break your code but will make commits and pull requests show all kinds of irrelevant changes. Quite often people will just ignore them — it’s quite a hassle to go through and change.
There is a solution to this: You can get everyone on the team to set their local configs to automatic line endings.
# This will let you configure line-endings on an individual basis
git config core.eol lf
git config core.autocrlf input
Of course, that would mean making sure the new contributor does that and it’s so easy to forget to tell them. So how would we do it for the whole team? Well the way Git works is it checks for a config file in the repository at .git/config, then it checks the user’s system-wide config at ~/.git/config then checks the global config at /etc/gitconfig. These are all useful at times but it turns out that none of those can be set through the repository itself. You can add repository-specific configurations but that will not carry over to other members of the team.
There is, however, a file that does get committed to the repository. It’s called .gitattributes. You won’t have one by default, so make a new file and save it as “*.gitattributes*”. This file is used for setting attributes per file; for example, you could make git diff use exif data for image files instead of trying to diff a binary file. In this case, we can use a wildcard to make the setting work for all files, essentially acting as a team-wide config file.
# Adding this to your .gitattributes file will make it so all files
# are checked in using UNIX line endings while letting anyone on the team
# edit files using their local operating system's default line endings.
* text=auto
Auto-Collapse
It’s a well-known solution to add package-managed files (such as node_modules/) to the .gitignore file in order to keep compiled files locally and not add them to the repository. However, sometimes there are files that you do want to check in but don’t want to see each time in the pull request.
For this situation (at least on GitHub), you can add paths annotated with linguist-generated to your .gitattributes file and check that file in at the root of the repository. This will collapse the files in the pull request, so you can still see they were changed without the full contents of the change.
For example, if you have a Unity project, you would want to check-in your asset files but not actually care about them so you can add it to the attributes file like so:
*.asset linguist-generated
Use Git Blame More Often
This is a tip that Harry Roberts suggested in his post about Git, “Little Things I Like To Do With Git.” He says to alias git blame to git praise so it feels like a positive action. This seems like semantics — renaming something doesn’t change what it does at all. But whenever I’ve seen any team speak about using Git’s blame feature, everyone tenses up, and I certainly do, too. It’s a natural reaction to think it’s a negative thing… it really shouldn’t be!
It’s a powerful feature knowing who last touched the code you’re looking at. Not to blame them or even to praise them, but simply to ask the right person questions and to save time figuring out who to talk to.
Not only should you think of git blame as a good thing (call it ‘praise’ if you want to), but you should think of it as a communication tool that will help the entire team reduce confusion and prevent wasting time figuring out who knows about what. Some IDEs such as Visual Studio include this feature as annotations (without any negative connotation at all) of each function so you can instantly see who last modified it (and therefore who to talk to about it).
Git Blame For A Missing File
Recently, I saw a developer on the team trying to figure out who removed a file, when it was, and why it was removed. This seems like a useful time for git blame but that works based on lines in a file; it doesn’t help with stuff that isn’t there any more. There is, however, a solution. The old trusty git log. If you look at the log with no arguments, then you will see a long list of all the changes on the current branch. You can add a commit ID to see the log for that specific commit, but if you use -- (which we’ve used before to target a specific file), then you can get the log for a file — even one that no longer exists.
# By using -- for a specific file,
# git log can find logs for files that were deleted in past commits
git log -- missing_file.txt
Commit Message Template
One thing that eventually gets mentioned within teams is that commit messages could be improved. Maybe they could reference a project management tool’s ID for the bug the commit fixes or maybe you want to encourage some text instead of an empty message.
This one needs to be run manually each time someone clones the repository (as git config files are not committed to the repository), but it is handy because you can have a shared file in the repository (named anything you want) that can act as the commit message template.
# This sets the commit template to the file given,
# this needs to be run for each contributor to the repository.
git config commit.template ./template-file
Git As Automation
Git is powerful for automation. This is not immediately obvious but if you consider that it knows all of your past activity within the repository — plus that of other contributors — it has a lot of information that can be very useful.
Git Hooks
Quite often you will find that within a team you all want to be doing repeated tasks while you work. This could be ensuring tests and code linters pass before it lets you push using the pre-push hook, or to enforce a branch naming strategy using the pre-commit hook. Here on Smashing Magazine, Konstantinos Leimonis wrote an article titled “How To Ease Your Team’s Development Workflow With Git Hooks” which is all about improving workflow using Git Hooks.
Manual Automation
One of the key automation features that Git has is git bisect. This is something that many people have heard of but probably not used. The purpose of it is to work through the git tree (the history of commits) and work out where a bug was introduced. The simplest way to do this is manually; you run git bisect start, give it the good and bad commit IDs, then git bisect goodor git bisect bad for each commit.
This is more powerful than it seems at first because it doesn’t iterate linearly through the git log, which you could do manually and it would be a repetitive process. It, instead, uses a binary search so it’s an efficient way to go through the commits with the least amount of steps.
# Begin the bisect
git bisect start
# Tell git which commit does not have the bug
git bisect good c5ba734
# Tell git which commit does have the bug
git bisect bad 6c093f4
# Here, do your test for the bug.
# This could be running a script, doing a journey on a website, unit test etc.
# If the current commit has bug:
git bisect bad
# If the current commit does not have the bug
git bisect good
# This will repeat until it finds the first commit with the bug
# To exit the bisect, either:
# Go back to original branch:
git bisect reset
# Or stick with current HEAD
git bisect reset HEAD
# Or you can exit the bisect at a specific commit
git bisect reset <commit ID>
Taking It Further: Automating The Scientific Method
In his talk “Debugging With The Scientific Method,” Stuart Halloway explained how Git’s bisect functionality could be used to automate debugging. It focuses on Clojure but you don’t need to know that language to find the talk interesting and useful.
“Git bisect is actually partial automation of the scientific method. You write a little program that will test something and git will bounce back and fourth cutting the world in half each time until it finds the boundary at which your test changes.”
— Stuart Halloway
At first, git bisect can feel interesting and quite cool but in the end not very useful. Stuart’s talk goes a long way to showing how it’s actually counterproductive to debug in the way most of us usually do. If you, instead, focus on the empirical facts whether or not a test passes, you can run it against all commits since a working version and reduce the “feeling around in the dark” kind of debugging that we are used to.
So how do we automate git bisect? We pass it a script to run for each appropriate commit. Previously, I said we can manually run a script at each step of the bisect but if we pass it a command to run then it will automatically run the script at each step. This could be a script you write specifically to debug this one particular issue, or it could be a test (unit, functional, integration, any type of test could be used). So you could write a test to ensure the regression doesn’t happen again and use that test on previous commits.
# Begin the bisect
git bisect start
# Tell git which commit does not have the bug
git bisect good c5ba734
# Tell git which commit does have the bug
git bisect bad 6c093f4
# Tell git to run a specific script on each commit
# For example you could run a specific script:
git bisect run ./test-bug
# Or use a test runner
git bisect run jest
On Every Commit In The Past
One of the strengths of git bisect is the efficient use of binary searches to iterate through history in a non-linear way. However, sometimes a linear crawl through history is exactly what you need. You could write a script that reads git log and loops through each commit executing code, but there’s a familiar command that can do this for you git rebase.
Kamran Ahmed wrote a tweet about using rebase to run a test suite on every commit to see which commit fails the test:
Find the commit that broke the tests
$ git rebase -i –exec “yarn test” d294ae9
This will run “yarn test” on all the commits between d294ae9 and HEAD and stop on the commit where the tests fail
We’ve already looked at using git bisect to do this efficiently so that’s generally more useful for this use-case, but what if we could have all of the other use-cases running a script for a given set of commits?
There’s room to be creative here. Maybe you want a way to generate a report of how your code has changed over time (or maybe show history of tests) and parsing the git log is not enough. This is perhaps the least directly useful trick in this article, but it’s interesting and raises the possibility of doing things that maybe we wouldn’t realise is possible.
# This will run for every commit between current and the given commit ID
git rebase -i --exec ./my-script
Further Reading
It’s impossible to more than scratch the surface of git in an article — it would end up being a book! In this article, I have chosen little tricks that could be new to even someone that’s been using git for years.
There’s so much more to Git from the foundations through to complex scripting, precise configurations and integrating into the terminal, so here are some resources to look at if this has piqued your interest:
Git Explorer
This interactive website makes it easy to figure out how to achieve what you are trying to do.
Dang it Git!
Everyone at some point gets lost in git and doesn’t know how to solve an issue. This gives solutions to a lot of the most common issues people have.
Pro Git
It’s a book and yet it is available online for free too, so Pro Git is an invaluable resource for understanding git.
Git Docs
It’s become a meme to tell developers to read the manual, but seriously both the git docs website and man git (for example man git-commit) go into detail about the internals of git and can be really useful.
Thoughtbot
The git category on Thoughtbot has some very useful tips for using git.
Git Hooks
The git hooks website has resources and ideas for all the available git hooks.
Demystifying Git Internals
Trees, blobs… these terms can seem a bit odd. This article explains some of the fundamentals of how Git works internally which can be useful (as shown already) to use Git to it’s full potential.
Little Things I Like To Do With Git
It was this article by Harry Roberts that made me realise how much more there is to Git after you’ve learned enough to move code around.
In previous articles, we explained what consistency is, the difference between “strong” and “eventual” consistency, and why this distinction is more important than ever to modern application developers. We also introduced the notion of ‘consistency tax’: the extra time and effort that a development team needs to invest if they choose a system with only eventual consistency or limited consistency guarantees.
Several modern databases use state-of-the-art algorithms to eliminate the tradeoff between consistency and performance. Of course, we would not want you to take our word for it without a proper explanation. Therefore, in this final article, we dive into the technical details behind some of these databases. Typically, the only source of information for these technical details are research papers, so the point of this article is to explain these systems in simpler terms. Because these systems are far more complex in reality, we’ll provide the links in the text in case you want to know more and love to read research papers.
Introduction
In parts 1 and 2 of this article series, we explained how distributed databases use different replicas to spread the load and/or serve users in different regions. To summarize here, for new readers, a replica is just a duplication of your data. And this duplication can live either in the same location for redundancy, or in another location to offer lower latencies to users in those locations. Having multiple replicas that can handle both reads and writes has a strong advantage, because the database becomes scalable and can offer lower latency to all your users, no matter where they are. However, you do not want each of the replicas to have their own interpretation of the data. Instead of small data differences between each replica, you want one unique interpretation of the data, which is often referred to as a single source of truth. In order to achieve that, you need to have some sort of agreement on data changes. We need a consensus.
Waiting for consensus
Every distributed database that aims to be consistent has multiple replicas that have to agree on the outcome of transactions. If conflicting data updates happen these replicas have to agree which update goes through and which doesn’t. This is called “consensus.”
Let’s go back to our game to exemplify why we need consensus. Imagine that the player of our game only has 3 gold pieces left, but tries to simultaneously buy two different items from two different shops for a total budget larger than the remaining 3 gold pieces. This involves two transactions, one for each item/shop, which we denote as t1 and t2. And let’s pretend that the owners of the shops are across the globe from each other, so the transactions take place on two different replicas. If both of the transactions are accepted the user would be able to buy more than he can afford. How do we prevent the user from overspending?
An example of two replicas that each receive a transaction (t1) and (t2). If we let both go through it would violate our business rule that users can’t spend more than they own. Clearly these replicas need decide which transaction is allowed and which should be blocked.
We know that these replicas need to communicate in order to agree on the final outcome of the two transactions. What we don’t know is how much communication they need. How many messages have to go back and forth between replica 1 and replica 2 in order to agree which transaction gets priority and which one gets cancelled?
As replicas in a distributed database are meant to serve users from different regions in the world with low latency, they are far apart by nature. By placing duplicates of the data closer to the end users, these users can read with lower latencies. However, when writes happen, the replicas need to send messages to each other to update all duplicated data uniformly–and these messages can take several 10s of milliseconds because they’re bridled by the speed of light as they travel across the globe. It’s clear that we need to keep the number of cross-data center messages as small as possible so that the end user isn’t left waiting around for these replicas across the globe to come to consensus.
For a long time, it had been thought to be impossible or impractical to do this. But today, several technologies exist to keep the number of round-trips low and bring latency within normal bounds.
The distance between New York and Paris is 5,839 km. For light to travel from New York to Paris and then back again would take 40 milliseconds.
If it takes a minimum of 40 milliseconds to travel between New York and Paris, a round-trip would take at least 80ms. The most important question that remains is: “How many round-trips do we need to execute transactions?” The answer to this question depends largely on the algorithms that are used.
How to reach agreement?
It appears that in order to achieve consensus about something, you need at least four hops (or two rounds of communication): one round to let each replica know that you are about to do something, then a second round to actually execute the action once everyone agrees that this action can be executed. This is something called distributed two-phase commitwhich is used by almost any distributed database. Let’s look at an analogy. Imagine you have to agree with a group of people on a good date for a party. It might go like this:
First, Polly asks everyone if they can make it to a party on Monday; she now knows that everyone can actually come to the party. Next, she needs to let everyone know that the party will indeed be on Monday, and people acknowledge that they will be there.
These are very similar to the two phases in two-phase commit. Of course, databases don’t party so the phases have different functions. In the case of a distributed system, the phases are called:
Prepare or request to commit: make sure that everyone knows about the transaction. In this phase, replicas in a distributed database store the query in some kind of todo list (a transaction log) on the disk to make sure they still know what to do if the server goes down.
Commit: actually calculate the results and store them
Of course, as always, it’s never that simple. There are many flavors of such algorithms. For example, there are improvements of two-phase commits called Paxos and Raft and even many variants of these (multi paxos/fast paxos/…). These alternatives aim to improve issues of availability or performance. To understand the availability issues, simply imagine that Polly falls sick or Amber’s phone dies. In the former case, she would be unable to continue her work as party coordinator and in the latter case, it would temporarily be impossible for Polly to know whether Amber agrees on the party date. Raft and Paxos improve on this by only requiring the majority to answer and/or selecting a new coordinator automatically when the leader or coordinator goes down. A good animation that shows how Raft works can be found here.
Agree about what?
Can we conclude that each distributed database then requires 2 round trips to write/read data? No, the reality is more complex than that. On one side, there are many possible optimizations and on the other side, there might be multiple things we need to agree on.
Agree on the time of a transaction
Agree whether reads can be executed
Agree whether reads can be executed
The simplest example that has multiple two-phase commit rounds is probably Cassandra’s light-weight transactions. They first require consensus agreements on reads and then consensus on writes.If each message takes 40ms to travel, this means the entire transaction requires 320ms or longer–depending on the required “locks” as we’ll explain later.
This is fairly easy to understand, but there are some issues with the implementation since Cassandra was never designed to be strongly consistent. Does that mean that strongly consistent databases are even slower? Not at all! Modern distributed databases use a mix of interesting features to achieve better performance.
Waiting for locks
Not only do we need to wait for messages to come to an agreement, but almost every distributed database will also use “locks”. Locks guarantee that the data about to be altered by a transaction is not being simultaneously altered by another transaction. When data is locked, it can’t be altered by other transactions, which means that these transactions have to wait. The duration of such a lock, therefore, has a big impact on performance. Again, this performance impact depends on the algorithm and optimizations that were implemented by the database. Some databases hold locks longer than others and some databases do not use locks at all.
Now that we know enough basics, let’s dive into the algorithms.
Modern Algorithms for Consensus
We now know that consensus and locks are the main bottlenecks that we need to optimize. So let’s go back to the main question of this article: “How does new technology lower these latencies within acceptable bounds?” Let’s start off with the first of these modern algorithms, which sparked interesting ideas for the rest of the database world.
2010 – Percolator
Percolator is an internal system built upon BigTable (one of the early NoSQL databases built by Google) that Google used to make incremental updates to their search index’s page crawling speed. The first paper on Percolator was released in 2010, inspiring the first distributed database inspired by it: FoundationDB in 2013. FoundationDB then got acquired by Apple to finally release a stable version in 2019, together with the release of a FoundationDB paper.
Although Percolator allowed Google to speed up page crawling significantly, it was not originally built as a general-purpose database. It was rather intended to be a fast and scalable incremental processing engine to support Google’s search index. Since the search index had to be scalable, many calculations had to happen on many machines concurrently, which required a distributed database. As we learned in the previous articles, programming against distributed systems that store data can be very complex, and traditionally required that developers pay a ‘consistency tax’ to program around unpredictable database behavior. To avoid paying so high a consistency tax, Google adopted a strong consistency model when they built Percolator.
The consistency model of Percolator could not exist without two key ingredients: versioning, and the Timestamp Oracle
Ingredient 1: Versioning
As we mentioned in previous articles, strong consistency requires us to agree on a global order for our transactions. Versioning is one of the elements that will be crucial to many of these algorithms since it can be used for failure recovery, to help replicate data, and to support a consistency model called ‘snapshot isolation’.
Versioning helps in failure recovery when a node fails or gets disconnected. When the node comes back online, thanks to the versions, it can easily restore its state by starting at the last snapshot that it was able to save, and then replaying the transactions based on the versions in another node. All it has to do is ask another node: “Hey, what has changed since I was gone?” Without versioning, it would have to copy over all the data, which would have put a huge strain on the system.
Failure recovery is great, but the strongest advantage lies in the fact that such a versioning system can be used to implement a strong consistency model. If the versioning system keeps versions for each data change, we can actually go back in time and do queries against an earlier version of our data.
Some bright minds found out that this historical querying capability could be used to provide a consistency model called ‘snapshot consistency’. The idea of snapshot consistency is to pick a version of the data at the beginning of the query, work with that version of the data during the rest of the query, then write a new version at the end of the query.
There is one possible pitfall here: during the execution of such a query, another query could be writing data that conflicts with the first query. For example, if two write queries start with the same snapshot of a bank account with $1000 on it, they could both spend the money since they do not see the writes of the other query. To prevent that, an additional transaction will take place to see if the snapshot’s values changed before either query writes a result. If something conflicting did happen to change the snapshot’s value, the transaction is rolled back and has to be restarted.
However, there is still one problem Percolator needs to solve. Clocks on different machines can easily drift apart a few 100s of milliseconds. If data for a query is split over multiple machines such as in our initial example, you can’t simply ask both machines to give you data at a certain timestamp since they have a slightly different idea of what the current time is. It’s a matter of milliseconds, but when many transactions have to be processed, a few milliseconds are all it takes to go from correct data to faulty data.
Time synchronization brings us to the second Percolator ingredient.
Ingredient 2: The Timestamp Oracle
Percolator’s solution to the time synchronization problem is something called the Timestamp Oracle. Instead of letting each node dictate its own time (which was not accurate enough), Percolator uses a central system that exposes an API providing you with a timestamp. The node on which this system lives is the Timestamp Oracle. When we keep multiple versions of our data, we need at least two timestamps for each query. First, we need a timestamp to query a snapshot, which we will use to read data. Then, at the end of the transaction when we are ready to write, we need a second timestamp to tag the new data version. As a result, Percolator has the disadvantage that it needs at least two calls to the Timestamp Oracle, which introduces even more latency if the Oracle is in another region from the nodes where the calls originated. When Google came up with their Distributed Database Spanner, they solved this problem.
2012 – Spanner
Spanner was the first globally distributed database to offer strong consistency, which essentially means that you get low latency reads without having to worry about potential database errors anymore. Developers no longer need to invest extra work to circumvent potential bugs caused by eventual consistency. The paper was released in 2012 and it was released to the general public in 2017 as Spanner Cloud.
Ingredient 1: Versioning
Google built Spanner after their experience with Percolator. Since Percolator’s versioning system proved to work, they kept this in Spanner’s design. This versioning system provided the ability to do very fast reads (snapshot reads) if you were willing to give up consistency. In that case, you could run queries and give Spanner a maximum age of the results. For example: “Please return my current inventory as fast as possible, but the data can only be 15 seconds old”. Basically, instead of abandoning consistency, you could now choose for each query which consistency level suited your use-case.
Ingredient 2: TrueTime
To eliminate the extra overhead to synchronize time between machines, Spanner abandoned the Timestamp Oracle in favor of a new concept called TrueTime. Instead of having one central system that provides a unified view of time, TrueTime tries to reduce the clock drift between the machines themselves. Engineers at Google managed to limit local clock drift by implementing a time synchronization protocol based on GPS and atomic clocks. This synchronization algorithm allowed them to limit clock drift within a boundary of 7ms, but required specific hardware that consisted of a combination of GPS and Atomic clock technology.
Of course, there is still a potential clock drift of 7ms, which means that two servers could still interpret a timestamp to be two different snapshots. This is solved by the third ingredient for Spanner: commit-wait.
Ingredient 3: Commit-wait
In fact, the TrueTime API does not return one timestamp but returns and interval n which it is sure that the current timestamp should lie. Once it is ready to commit, it will just wait a few milliseconds to cope with the potential drift which is called ‘Commit-wait’. This makes sure that the timestamp that will be assigned to the write is a timestamp that has passed on all nodes. It’s also the reason that running Spanner on commodity hardware can not deliver the same guarantee since the wait period would need to be a few 100s of milliseconds.
2012 – Calvin
The first paper on the Calvin algorithm was released in 2012, from research at Yale. Just like the previous approaches, Calvin consists of several ingredients. Although versioning is also part of it, the rest of the approach is radically different which requires a few extra ingredients to work: deterministic calculations, and the separation of ordering from locking. These are ingredients that are typically not found in databases with traditional architecture. By changing the architecture and accepting that queries have to be deterministic, Calvin can reduce the worst-case number of cross- datacenter messages totwo. This pushes down the worst-case latency of global transactions significantly and brings it below 200ms or theoretically even below 100ms. Of course, in order to believe that this is possible, you might want to know how it works first, so let’s take a look at the algorithm.
Ingredient 1: Versioning
Similar to Percolator and Spanner, Calvin relies on versioned data. These snapshots in Calvin are mainly used to ensure fault-tolerance. Each node stores different snapshots which can be considered as checkpoints. A disconnected node that comes back online only needs to grab the timestamp of the last checkpoint it has witnessed, and then ask another node to inform him of all the transactions that came after that checkpoint.
Ingredient 2: Deterministic calculations
Many front-end developers will have heard of the Elm frontend framework which implements a React Redux-like workflow. Elm has a steeper learning curve than similar JavaScript-based frameworks because it requires you to learn a new language. However, because the language is functional (no side-effects), Elm allows some impressive optimizations. The key is that functions in Elm give up destructive manipulations to be deterministic. You can run the same function with the same input twice and it will always yield the same result. Because they are deterministic, Elm queries can now more efficiently decide how to update views.
Similar to Elm, Calvin has given up something to speed up the calculations. In the case of Calvin, we can basically say that the result of a transaction will be the same, whether it’s executed on machine A or Machine B. This might seem evident, but typically databases do not guarantee this. Remember that SQL allows you to use the current time or allows something called interactive transactions where user input can be inserted in the middle of a transaction, both of which could violate the guarantees provided by Calvin.
To achieve deterministic calculations, Calvin (1) needs to take out calculations such as current time and pre-calculate them, and (2) does not allow interactive transactions. Interactive transactions are transactions where a user starts a transaction, reads some data, provides some additional user input in the middle, and then finally does some extra calculations and possibly some writes. Since the user is not predictable, such a transaction is not deterministic. In essence, Calvin trades in a minor convenience (interactive transactions) for great performance.
Ingredient 3: Separate the problem of ordering.
Databases spend a lot of time negotiating locks in order to make it look like the system is executing in a specific order”. If an order is all you need, maybe we can separate the problem of locking from the problem of ordering. This means though that your transactions have to be pure.
— Kyle Kingsbury
Separating the concern of ordering transactions from the actual execution has been considered many times in the database world but without much success. However, when your transactions are deterministic, separating the ordering from the calculations actually becomes feasible. In fact, the combination of deterministic calculations and the separation of ordering from the rest of the algorithm is extremely powerful since it helps to reduce lock duration and greatly diminishes the slower communication between distant nodes (cross-datacenter communication).
Shorter lock duration
Whenever locks are held on a piece of data, it means that other queries that use that data have to wait. Therefore, shorter locking results in better performance. Below is an image that shows an overview of the locking procedure in Calvin compared to how a traditional distributed database might do it. Most databases would keep a lock on data until there is at least a consensus on what to write while Calvin would only keep the lock until all nodes agree on the order. Because the calculations are deterministic and they all agreed on the order, each node will calculate separately and come to the same end result.
Less communication between distant nodes
Besides the advantages in lock duration, separating ordering from the rest of the algorithm also requires less communication. As explained before with the Cassandra example, a distributed database typically requires cross-datacenter communication in many phases of their algorithm. In the case of Calvin, the only moment we need to agree on something is at the moment we determine the order. With the Raft protocol, this could be done in two hops which makes it possible to achieve sub 100ms latencies for read-write queries.
Together with the reduced lock time, this also brings superb throughput. The original Calvin paper has also done experiments that show that this approach significantly outperforms traditional distributed database designs under high contention workloads. Their results of half a million transactions per second on a cluster of commodity machines are competitive with the current world record results obtained on much higher-end hardware.
Run on any hardware
Besides that, Calvin has another advantage: it no longer requires specific hardware in order to obtain such results. Since Calvin can run on commodity machines, it can run on any cloud provider.
FaunaDB has its own distributed transaction protocol with some similarities to Calvin. Just like the former approaches, FaunaDB’s data is also versioned. Since versioning is not only useful for the consistency model but can also have business value, FaunaDB has upgraded this mechanism to a first-class citizen that can be used by end-users. This feature essentially allows time-traveling queries. End-users can execute a query on historic data to answer questions such as: “What would the result of this query have been 20 days ago?”. This is useful to recover data that was accidentally overwritten, audit data changes, or simply incorporate time-travel in your application’s features.
Ingredient 2 and 3: Deterministic calculations and Separation
Like Calvin, FaunaDB also has deterministic calculations and separates the problem of ordering from the rest of the algorithm. Although there are similarities, calculating transactions in FaunaDB happens in a different phase than Calvin. Where Calvin takes advantage of the deterministic nature to execute the same transaction multiple times once the order is set, FaunaDB will calculate only once prior to consensus on the order of the transactions. Which brings us to the fourth ingredient.
Ingredient 4: Optimistic calculation
FaunaDB adds a fourth ingredient which we have seen already when we talked about Snapshot Isolation: Optimistic calculations instead of locking.
FaunaDB will not lock, but will instead optimistically calculate the result of the transaction once in the node where the transaction was received, and then add the result and the original input values to the log. Where Calvin would have saved the query that needs to be executed in the transaction log, FaunaDB will save both the result of the calculation and the original input values in the log. Once there is consensus on the order in which the results have to be applied, FaunaDB will verify whether the input data for that calculation has changed or not (thanks to versioning). If the input values have changed, the transaction is aborted and restarted, if they have remained the same, the results are applied on all nodes without any extra calculation.
FaunaDB’s algorithm has similar advantages as Calvin, but reduces the amount of required calculations in the cluster.
Conclusion
In this series, we have explained how strong consistency can help you build error-free applications more efficiently. In this last article, we have further explained how revolutionary ideas can power a new generation of distributed databases that are both consistent and performant. The takeaway in the previous articles was: “Consistency matters”. In this final article, the takeaway is encompassed in the following:
In the near future, if you read a phrase such as:
“Many NoSQL databases do not offer atomic writes for multiple documents, and in return give better performance. And while consistency is another great feature of SQL databases, it impedes the ability to scale out a database across multiple nodes, so many NoSQL databases give up consistency.” – the biggest challenges of moving to NoSQL
Realize that modern algorithms enable databases to deliver consistency without centralization. In this article, we have seen a few examples of algorithms and databases that do this. Databases that build upon these algorithms are a next generation of databases that no longer can be described by simple categories such as NoSQL, SQL, or even NewSQL.
With distributed cloud databases based on Percolator, Spanner, Calvin, and FaunaDB’s transaction protocol, you can have highly performant distributed databases that offer stronger consistency models. This means that you can build data-intensive applications that offer low-latency without having to worry about data errors, performance, or service provisioning. In such systems, consistency is transparent, and you do not have to think about it as a developer. The next time you choose a database, pick one that is consistent by default.
In this piece, Eric Meyer argues that performance is more important than ever right now — especially for websites that contain critical information for the public:
If you are in charge of a web site that provides even slightly important information, or important services, it’s time to get static. I’m thinking here of sites for places like health departments (and pretty much all government services), hospitals and clinics, utility services, food delivery and ordering, and I’m sure there are more that haven’t occurred to me. As much as you possibly can, get it down to static HTML and CSS and maybe a tiny bit of enhancing JS, and pare away every byte you can.
What Eric means by “it’s time to get static” is that we need to serve regular ol’ HTML, CSS, and JavaScript files to the browser with server-side rendering. That way, our sites are faster and with fewer bottlenecks that can render the whole website useless.
On this note, Zach Leatherman recently looked at 200 sites built with Eleventy and found that the mean Lighthouse performance score was 93.7! In other words: static site generators are gosh darn fast. And if that’s not a great reason to make the switch or to start learning about static site generators in general, then I don’t know what is.